Getting Started
Installing Huff
The Huff Neo Compiler is built in Rust to create an extremely performant experience compiling huff.
Installation of the compiler is similar to that of Foundry.
First, install hnc-up, a version control manager for the Huff Compiler:
curl -L https://raw.githubusercontent.com/cakevm/huff-neo/main/hnc-up/install | bash
NOTE: This installs the hnc-up binary, but does not guarantee it is added to your path. If you get an error like hnc-up: command not found, you will need to source your path by running source ~/.bashrc or source ~/.zshrc. Alternatively, you can open a new terminal window.
Now, with hnc-up installed and in your path, you can simply run hnc-up to install the latest stable version of hnc (the huff compiler).
On Windows, build from the source
If you use Windows, you can build from the source or download the binary form the releases to get huff.
Building from the source
Download and run rustup-init from rustup.rs. It will start the installation in a console.
If you encounter an error, it is most likely the case that you do not have the VS Code Installer which you can download here and install.
After this, run the following to build huff from the source:
cargo install --git https://github.com/cakevm/huff-neo.git hnc --bins --locked
To update from the source, run the same command again.
🎉 TADA, Huff is installed! 🎉
To verify for yourself that it’s installed, run hnc --help to view the help menu.
To get started compiling Huff Contracts, check out compiling.
To diver deeper into the compiler’s cli abilities, check out the cli docs.
About Huff
Huff is a low-level programming language designed for developing highly optimized smart contracts that run on the Ethereum Virtual Machine (EVM). Huff does not hide the inner workings of the EVM and instead exposes its programming stack to the developer for manual manipulation.
While EVM experts can use Huff to write highly-efficient smart contracts for use in production, it can also serve as a way for beginners to learn more about the EVM.
If you’re looking for an in-depth guide on how to write and understand Huff, check out the tutorials.
History of the Huff Language
The Aztec Protocol team originally created Huff to write Weierstrudel, an on-chain elliptical curve arithmetic library that requires incredibly optimized code that neither Solidity nor Yul could provide.
Comparison to huff-rs
There is huff-rs and huff-neo?
Yes, there are two versions of the Huff compiler. The original compiler, huff-rs is no longer maintained. There is a plan to revive it as huff2, but since it is a new development from scratch, it is unknown when it will have feature parity with the original compiler. huff-neo tries to step-in and continues the development and also tries to evolve the Huff language where necessary.
New in huff-neo
There are some new features in huff-neo that are not available in huffc.
Allowed use of built-in functions for constants and code tables
The usage of built-in functions for constants and code tables is now possible.
#define constant FUNC_TEST = __FUNC_SIG("test(uint256)")
#define constant BYTES_HELLO = __BYTES("hello")
#define code_table TEST_TABLE {
0x123
__FUNC_SIG("test(uint256)")
__BYTES("hello")
__LEFTPAD(__FUNC_SIG("test(uint256)")) // New built-in function __LEFTPAD
[FUNC_TEST]
[BYTES_HELLO]
}
Arithmetic expressions in constants
Constants can use arithmetic expressions evaluated at compile time.
#define constant BASE = 0x20
#define constant OFFSET = 0x04
#define constant COMBINED = [BASE] + [OFFSET] // 0x24
#define constant WORD_SIZE = 0x20
#define constant HALF_WORD = [WORD_SIZE] / 0x02 // 0x10
#define constant COMPLEX = (0x0a + 0x05) * 0x02 // 0x1e
Supported operators: +, -, *, /, % (binary), - (unary). Parentheses () for grouping. See the Constants documentation for details.
New builtin constant: __NOOP
A special constant that generates no bytecode, useful for optional macro arguments and conditional compilation patterns.
// Macro with optional operation
#define macro EXECUTE_OPTIONAL(op) = takes(0) returns(0) {
<op> // Can be __NOOP to skip this operation
0x01 0x02 add
}
// With operation
EXECUTE_OPTIONAL(pop) // Generates: pop, push 0x01, push 0x02, add
// Without operation (generates no extra bytecode)
EXECUTE_OPTIONAL(__NOOP) // Generates: push 0x01, push 0x02, add
See the Builtin Constants documentation for details.
New builtin functions
There are new builtin functions available in huff-neo.
__LEFTPAD- Left pads a hex input or the result of a passed builtin in a code table.__BYTES- Converts a string to the UTF-8 representation bytes and pushes it to the stack.__ASSERT_PC- Validates bytecode position at compile-time to ensure instructions are at expected offsets.
__BYTES() example
#define macro MAIN() = takes (0) returns (0) {
__BYTES("hello") // Will push UTF-8 encoded string (PUSH5 0x68656c6c6f)
}
__ASSERT_PC() example
Validates that bytecode is positioned at expected offsets, useful for ensuring jump destinations align correctly. Can be combined with for-loops and constants for precise bytecode positioning.
#define constant TARGET_OFFSET = 0x20
#define macro MAIN() = takes(0) returns(0) {
__ASSERT_PC(0x00) // Assert we're at the start
// Fill space to reach target offset using for-loop with constant
for(i in 0..[TARGET_OFFSET]) {
stop // Expands to 32 stop instructions = 32 bytes
}
__ASSERT_PC([TARGET_OFFSET]) // Assert we're at byte 32
target: // Label for jump destination
}
See the Builtin Functions documentation for complete details.
First-class macros
Macros can now be passed as arguments to other macros and invoked dynamically, making code more reusable and flexible.
#define macro ADD(a, b) = takes(0) returns(1) {
<a> <b> add
}
#define macro APPLY(fn, x, y) = takes(0) returns(1) {
<fn>(<x>, <y>) // Invoke macro with arguments
}
#define macro MAIN() = takes(0) returns(0) {
APPLY(ADD, 0x05, 0x06) // Expands to: 0x05 0x06 add
}
See the Macros and Functions documentation for more details.
Compile-time for loops
Generate repetitive code patterns at compile-time using for loops that expand before bytecode generation.
#define constant COUNT = 10
#define macro INIT_STORAGE() = takes(0) returns(0) {
// Initialize storage slots 0 through 9 with zero
for(i in 0..[COUNT]) {
0x00 <i> sstore
}
}
#define macro PUSH_SEQUENCE() = takes(0) returns(5) {
// Generate: 0x00 0x02 0x04 0x06 0x08
for(i in 0..10 step 2) {
<i>
}
}
See the Compile-Time Loops documentation for complete details and examples.
Compile-time if/else statements
Generate conditional code at compile-time using if/else/else if statements that expand before bytecode generation. Only the matching branch is compiled into the final bytecode.
#define constant MODE = 0x01
#define constant DEBUG = 0x00
#define macro MAIN() = takes(0) returns(0) {
if ([MODE] == 0x01) {
// This code is compiled (condition is true)
0xAA 0x00 mstore
} else if ([MODE] == 0x02) {
// Not compiled
0xBB 0x00 mstore
} else {
// Not compiled
0xCC 0x00 mstore
}
// Supports logical NOT
if (![DEBUG]) {
// This code is compiled (DEBUG is 0, !0 = 1)
0xFF 0x00 mstore
}
}
Supported features:
- Comparison operators:
==,!=,<,>,<=,>= - Logical NOT:
! - Arithmetic expressions:
([A] + [B]) > [C] - Nested if statements
- If/else if/else chains
See the Compile-Time Conditionals documentation for complete details and examples.
New test capabilities
The test module has been refactored to use anvil and forge features from foundry to fork the mainnet. This allows for more advanced testing capabilities.
Compile a contract
Compiling Contracts with the Huff Compiler
NOTE: Installing the Huff Compiler is a prerequisite for compiling contracts. See installing to install hnc.
Below we outline the few steps it takes to compile a Huff contract.
1. Create a file called addTwo.huff and enter the following:
#define function addTwo(uint256,uint256) view returns(uint256)
#define macro MAIN() = takes(0) returns(0) {
// Get the function selector
0x00
calldataload
0xE0
shr
// Jump to the implementation of the ADD_TWO function if the calldata matches the function selector
__FUNC_SIG(addTwo) eq addTwo jumpi
addTwo:
ADD_TWO()
}
#define macro ADD_TWO() = takes(0) returns(0) {
0x04 calldataload // load first 32 bytes onto the stack - number 1
0x24 calldataload // load second 32 bytes onto the stack - number 2
add // add number 1 and 2 and put the result onto the stack
0x00 mstore // place the result in memory
0x20 0x00 return // return the result
}
2. Use hnc to compile the contract and output bytecode:
hnc addTwo.huff --bytecode
This will output something similar to:
600c8060093d393df35f35602035015f5260205ff3
You can find an in-depth explanation of this contract in The Basics tutorial.
Huff Project Template
Huff has a project template to make it easier to get started writing Huff contracts!
Using the Template
After navigating to https://github.com/cakevm/huff-neo-project-template, you can click the Use this template button on the top right of the repository to create a new repository containing all the template’s code.
Once you’ve cloned and entered into your repository, you need to install the necessary dependencies. In order to do so, simply run:
forge install
Then, you can build and/or run tests with the following commands:
forge build
forge test
Inside the template, there is a contract in the src/ directory (the default location for huff contracts) called src/SimpleStore.huff. This contract demonstrates a simple contract to set and get values stored in the contract, with the functions being (as defined by the function annotations at the top of the contract):
function setValue(uint256);
function getValue() view returns (uint256);
Inside the test/ directory, there are tests for the src/SimpleStore.huff contract in test/SimpleStore.t.sol. Since Foundry doesn’t natively support compiling huff code, huff projects have to use the foundry-huff library to be able to compile huff code using forge commands.
NOTE: In order to compile huff code, foundry-huff behind the scenes need the Huff Neo Compiler to be installed.
Returning back to our test contract test/SimpleStore.t.sol, we can run the following command to run all tests: forge test.
Other Template Features
Once you have created a new repository from the project template, there are a few things to note before digging in and writing your huff contracts.
The foundry.toml file located in the root of the project template, contains the configuration for using the forge toolchain.
Inside ./.github/workflows there is a GitHub action file that will run CI using the Foundry toolchain and the huff-toolchain.
Huff by Example
Introduction
Huff by Example is an effort to provide a thorough explanation of each feature of the Huff language, along with code-snippet examples detailing how, when, where, and why to use each one. The snippets here are heavily commentated, but this section does assume some prior experience working with the EVM.
If you are new to low-level EVM programming, please read the Tutorials section of the docs before diving into Huff development. If you run into any issues, please feel free to come ask the community questions on Telegram.
Macros and Functions
Huff offers two ways to group together your bytecode: Macros and Functions. It is important to understand the difference between the two, and when to use one over the other.
Both are defined similarly, taking optional arguments as well as being followed
by the takes and returns keywords. These designate the amount of stack
inputs the macro/function takes in as well as the amount of stack elements the
macro/function outputs. The takes and returns keywords are optional - if they are
not present, the value will default to 0.
#define <macro|fn> TEST(err) = takes (1) returns (3) {
// ...
}
Macros
Most of the time, Huff developers should opt to use macros. Each time a macro is invoked, the code within it is placed at the point of invocation. This is efficient in terms of runtime gas cost due to not having to jump to and from the macro’s code, but it can quickly increase the size of the contract’s bytecode if it is used commonly throughout.
Note: Labels defined within macros have their own scope. See Label Scoping for details on how labels work across macro invocations.
Constructor and Main
MAIN and CONSTRUCTOR are two important macros that serve special purposes. When
your contract is called, the MAIN macro will be the fallback, and it is commonly where
a Huff contract’s control flow begins. The CONSTRUCTOR macro, while not required,
can be used to initialize the contract upon deployment. Inputs to the CONSTRUCTOR macro
are provided at compile time.
By default, the CONSTRUCTOR will add some bootstrap code that returns the compiled MAIN macro
as the contract’s runtime bytecode. If the constructor contains a RETURN opcode, the compiler
will not include this bootstrap, and it will instead instantiate the contract with the code returned
by the constructor.
Table scopes in CONSTRUCTOR and MAIN
Tables referenced via __tablestart sit in different parts of the deployment bytecode depending
on which scope references them:
[ctor_body][bootstrap][main_body][main_tables][ctor_only_tables][args]
==============================
runtime — stored on-chain
- Referenced from
MAIN→ emitted inside the runtime;__tablestart(T)is the offset within the runtime. - Referenced only from
CONSTRUCTOR→ emitted in the deployment tail pastmain. The constructor can read it during deployment, but it is not stored on-chain. - Referenced from both → emitted once in the runtime section. The constructor’s
__tablestart(T)resolves into that shared copy; no duplicate is written to the tail.
Example of a shared table read from both scopes:
#define table CONFIG {
0x00000000000000000000000000000000000000000000000000000000deadbeef
0x00000000000000000000000000000000000000000000000000000000cafebabe
}
#define macro CONSTRUCTOR() = takes (0) returns (0) {
// Copy CONFIG into memory at 0x00 and store the first word in slot 0.
__tablesize(CONFIG) __tablestart(CONFIG) 0x00 codecopy
0x00 mload 0x00 sstore
}
#define macro MAIN() = takes (0) returns (0) {
// Read the second word of CONFIG and return it.
__tablestart(CONFIG) 0x20 add 0x00 codecopy
0x20 0x00 return
}
Macro Arguments
Macros can accept arguments, which can be used within the macro itself or passed as reference. These arguments can be labels, opcodes, literals, constants, or other macro calls. Since macros are inlined at compile time, their arguments are also inlined and not evaluated at runtime.
Arguments can also be used in compile-time expressions within if conditions and for loop bounds using the <arg> syntax. See Compile-Time Conditionals and Compile-Time Loops for details.
First-Class Macros
Macros can be passed as arguments to other macros, allowing you to write more reusable and composable code. When a macro is passed as an argument, it can be invoked within the receiving macro using the <arg> syntax.
Basic Usage
To pass a macro as an argument and invoke it:
#define macro ADD_OP() = takes(2) returns(1) {
add
}
#define macro APPLY_OP(operation) = takes(0) returns(1) {
0x10
0x20
<operation>() // Invoke the macro passed as argument
}
#define macro MAIN() = takes(0) returns(0) {
APPLY_OP(ADD_OP) // Expands to: 0x10 0x20 add
}
Passing Arguments to Macro Arguments
You can also pass arguments when invoking a macro argument:
#define macro MUL_OP(a, b) = takes(0) returns(1) {
<a> <b> mul
}
#define macro COMPUTE(fn, x, y) = takes(0) returns(1) {
<fn>(<x>, <y>) // Invoke macro with arguments
}
#define macro MAIN() = takes(0) returns(0) {
COMPUTE(MUL_OP, 0x05, 0x06) // Expands to: 0x05 0x06 mul
}
Combining with Other Arguments
Macro arguments can be mixed with literals, opcodes, and other argument references:
#define macro CALC(val1, val2, op) = takes(0) returns(1) {
<val1> // First value
<val2> // Second value
<op> // Operation
}
#define macro WRAPPER(fn, num) = takes(0) returns(1) {
<fn>(0x10, <num>, add) // Mix literal, argument, and opcode
}
#define macro MAIN() = takes(0) returns(0) {
WRAPPER(CALC, 0x20) // Expands to: 0x10 0x20 add
}
Nested Macro Invocations
Macros can be passed through multiple levels and even invoke other macro arguments:
#define macro DOUBLE(x) = takes(0) returns(1) {
<x> 0x02 mul
}
#define macro PROCESS(fn, arg) = takes(0) returns(1) {
<fn>(<arg>()) // Invoke fn with the invocation of arg
}
#define macro MAIN() = takes(0) returns(0) {
PROCESS(PROCESS, DOUBLE) // Complex nesting
}
Example
// Define the contract's interface
#define function addWord(uint256) pure returns (uint256)
// Get a free storage slot to store the owner
#define constant OWNER = FREE_STORAGE_POINTER()
// Define the event we wish to emit
#define event WordAdded(uint256 initial, uint256 increment)
// Macro to emit an event that a word has been added
#define macro emitWordAdded(increment) = takes (1) returns (0) {
// input stack: [initial]
<increment> // [increment, initial]
__EVENT_HASH(WordAdded) // [sig, increment, initial]
0x00 0x00 // [mem_start, mem_end, sig, increment, initial]
log3 // []
}
// Only owner function modifier
#define macro ONLY_OWNER() = takes (0) returns (0) {
caller // [msg.sender]
[OWNER] sload // [owner, msg.sender]
eq // [owner == msg.sender]
is_owner jumpi // []
// Revert if the sender is not the owner
0x00 0x00 revert
is_owner:
}
// Add a word (32 bytes) to a uint
#define macro ADD_WORD() = takes (1) returns (1) {
// Input Stack: // [input_num]
// Enforce that the caller is the owner. The code of the
// `ONLY_OWNER` macro will be pasted at this invocation.
ONLY_OWNER()
// Call our helper macro that emits an event when a word is added
// Here we pass a literal that represents how much we increment the word by.
// NOTE: We need to duplicate the input number on our stack since
// emitWordAdded takes 1 stack item and returns 0
dup1 // [input_num, input_num]
emitWordAdded(0x20) // [input_num]
// NOTE: 0x20 is automatically pushed to the stack, it is assumed to be a
// literal by the compiler.
0x20 // [0x20, input_num]
add // [0x20 + input_num]
// Return stack: [0x20 + input_num]
}
#define macro MAIN() = takes (0) returns (0) {
// Get the function signature from the calldata
0x00 calldataload // [calldata @ 0x00]
0xE0 shr // [func_sig (calldata @ 0x00 >> 0xE0)]
// Check if the function signature in the calldata is
// a match to our `addWord` function definition.
// More about the `__FUNC_SIG` builtin in the `Builtin Functions`
// section.
__FUNC_SIG(addWord) // [func_sig(addWord), func_sig]
eq // [func_sig(addWord) == func_sig]
add_word jumpi // []
// Revert if no function signature matched
0x00 0x00 revert
// Create a jump label
add_word:
// Call the `ADD_WORD` macro with the first calldata
// input, store the result in memory, and return it.
0x04 calldataload // [input_num]
ADD_WORD() // [result]
0x00 mstore // []
0x20 0x00 return
}
Functions
Functions look extremely similar to macros, but behave somewhat differently.
Instead of the code being inserted at each invocation, the compiler moves
the code to the end of the runtime bytecode, and a jump to and from that
code is inserted at the points of invocation instead. This can be a useful
abstraction when a certain set of operations is used repeatedly throughout
your contract, and it is essentially a trade-off of decreasing contract size
for a small extra runtime gas cost (22 + n_inputs * 3 + n_outputs * 3 gas
per invocation, to be exact).
Functions are one of the few high-level abstractions in Huff, so it is important to understand what the compiler adds to your code when they are utilized. It is not always beneficial to re-use code, especially if it is a small / inexpensive set of operations. However, for larger contracts where certain logic is commonly reused, functions can help reduce the size of the contract’s bytecode to below the Spurious Dragon limit.
Function Arguments
Functions can accept arguments to be “called” inside the macro or passed as a reference. Function arguments may be one of: label, opcode, literal, or a constant. Since functions are added to the end of the bytecode at compile-time, the arguments are not evaluated at runtime and are instead inlined as well.
Example
#define macro MUL_DIV_DOWN_WRAPPER() = takes (0) returns (0) {
0x44 calldataload // [denominator]
0x24 calldataload // [y, denominator]
0x04 calldataload // [x, y, denominator]
// Instead of the function's code being pasted at this invocation, it is put
// at the end of the contract's runtime bytecode and a jump to the function's
// code as well as a jumpdest to return to is inserted here.
//
// The compiler looks at the amount of stack inputs the function takes (N) and
// holds on to an array of N SWAP opcodes in descending order from
// SWAP1 (0x90) + N - 1 -> SWAP1 (0x90)
//
// For this function invocation, we would need three swaps starting from swap3
// and going to swap1. The return jumpdest PC must be below the function's
// stack inputs, and the inputs still have to be in order.
//
// [return_pc, x, y, denominator] (Starting stack state)
// [denominator, x, y, return_pc] - swap3
// [y, x, denominator, return_pc] - swap2
// [x, y, denominator, return_pc] - swap1
//
// After this, the compiler inserts a jump to the jumpdest inserted at the
// start of the function's code as well as a jumpdest to return to after
// the function is finished executing.
//
// Code inserted when a function is invoked:
// PUSH2 return_pc
// <num_inputs swap ops>
// PUSH2 func_start_pc
// JUMP
// JUMPDEST <- this is the return_pc
MUL_DIV_DOWN(err) // [result]
// Return result
0x00 mstore
0x20 0x00 return
err:
0x00 0x00 revert
}
#define fn MUL_DIV_DOWN(err) = takes (3) returns (1) {
// A jumpdest opcode is inserted here by the compiler
// Starting stack: [x, y, denominator, return_pc]
// function code ...
// Because the compiler knows how many stack items the function returns (N),
// it inserts N stack swaps in ascending order from
// SWAP1 (0x90) -> SWAP1 (0x90) + N - 1 in order to move the return_pc
// back to the top of the stack so that it can be consumed by a JUMP
//
// [result, return_pc] (Starting stack state)
// [return_pc, result] - swap1
//
// Final function code:
// 👇 func_start_pc
// JUMPDEST [x, y, denominator, return_pc]
// function code ... [result, return_pc]
// SWAP1 [return_pc, result]
// JUMP [result]
}
Builtin Functions
Several builtin functions are provided by the Huff compiler. The functions can be used inside a macro, function definition to generate the desired bytecode. The usage of __RIGHTPAD, __FUNC_SIG and __BYTES is usable in a data table. The builtin functions are evaluated at compile time and substituted with the corresponding bytecode.
__FUNC_SIG(<string>|<function definition>)
At compile time, the invocation of __FUNC_SIG is substituted with PUSH4 function_selector, where function_selector is the 4 byte function selector of the passed function definition or string. If a string is passed, it must represent a valid function signature i.e. "test(address, uint256)"
__EVENT_HASH(<string>|<event definition>)
At compile time, the invocation of __EVENT_HASH is substituted with PUSH32 event_hash, where event_hash is the selector hash of the passed event definition or string. If a string is passed, it must represent a valid event signature i.e. "TestEvent(uint256, address indexed)"
__ERROR(<error definition>)
At compile time, the invocation of __ERROR is substituted with PUSH32 error_selector, where error_selector is the left-padded 4 byte error selector of the passed error definition.
__LEFTPAD(<string>|<hex>|<builtin function>)
At compile time, the invocation of __LEFTPAD is substituted with padded_literal, where padded_literal is the left padded version of the passed input. This function is only available as constant assignment or in a code table.
Example
__LEFTPAD(0x123)
// will result in 32 bytes:
0x0000000000000000000000000000000000000000000000000000000000000123
__RIGHTPAD(<string>|<hex>|<builtin function>)
At compile time, the invocation of __RIGHTPAD is substituted with PUSH32 padded_literal, where padded_literal is the right padded version of the passed input.
Example
__RIGHTPAD(0x123)
// will result in 32 bytes:
0x1230000000000000000000000000000000000000000000000000000000000000
__codesize(<macro>|<function>)
Pushes the code size of the macro or function passed to the stack.
__codesize(RUNTIME)
RUNTIME is a reserved argument that resolves at compile time to the byte length of the runtime section as the compiler emits it — MAIN’s body plus its appended runtime tables. Usable in both MAIN and CONSTRUCTOR (directly or via a derived #define constant).
The runtime size is self-referential when used from MAIN (the embedded value contributes to the size it measures). The compiler resolves this by iterating MAIN codegen to a fixed point — typically converges in 2–3 passes. EIP-170 bounds the value at PUSH2, so widths never grow beyond two bytes.
Not allowed inside a code table — code tables contribute to the runtime size, so embedding the runtime size inside one would create a circular dependency in table sizing. RUNTIME is also reserved as a macro name; #define macro RUNTIME() = { ... } is rejected.
This enables Solidity-style immutables without on-chain arithmetic. CONSTRUCTOR copies MAIN to memory, writes immutable values past it, and returns the combined region. MAIN reads each immutable at a compile-time literal offset:
#define constant IMMUTABLE_1 = __codesize(RUNTIME)
#define constant IMMUTABLE_2 = [IMMUTABLE_1] + 0x20
#define constant RETURN_LEN = [IMMUTABLE_2] + 0x20
#define macro CONSTRUCTOR() = {
// Copy MAIN to memory at offset 0.
[IMMUTABLE_1] __codesize(CONSTRUCTOR) 0x00 codecopy
// Append two immutables past it.
0x11 [IMMUTABLE_1] mstore
0x22 [IMMUTABLE_2] mstore
// Return runtime + immutables.
[RETURN_LEN] 0x00 return
}
#define macro MAIN() = {
// Read the second immutable at a compile-time literal offset.
0x20 [IMMUTABLE_2] 0x00 codecopy
0x20 0x00 return
}
__tablestart(<table>) and __tablesize(<table>)
These functions related to Jump Tables are described in the next section.
__VERBATIM(<hex>|<constant>|<builtin function>)
This function is used to insert raw hex data into the compiled bytecode without a PUSH opcode. It is useful for inserting raw opcodes or data into the compiled bytecode.
You can pass:
- A hex literal directly:
__VERBATIM(0x1234) - A constant reference:
__VERBATIM([MY_CONSTANT]) - A builtin function that normally generates PUSH + value
When wrapping a builtin function, __VERBATIM strips the PUSH opcode and emits only the raw value bytes.
Supported nested builtins:
__FUNC_SIG- emits 4-byte selector (without PUSH4)__EVENT_HASH- emits 32-byte hash (without PUSH32)__BYTES- emits N-byte UTF-8 (without PUSHX)__ERROR- emits error selector (without PUSH)__RIGHTPAD- emits 32-byte right-padded value (without PUSH32)__LEFTPAD- emits 32-byte left-padded value (without PUSH32)
Examples
Direct hex literal:
#define macro MAIN() = takes (0) returns (0) {
__VERBATIM(0x1234) // Inserts raw bytes 0x1234
}
Constant reference:
#define constant SIG = __FUNC_SIG("transfer(address,uint256)")
#define macro MAIN() = takes (0) returns (0) {
__VERBATIM([SIG]) // Inserts the function selector bytes
}
Nested builtin function:
#define macro MAIN() = takes (0) returns (0) {
// __FUNC_SIG normally produces: 632e1a7d4d (PUSH4 + selector)
// __VERBATIM strips the PUSH4, emitting just: 2e1a7d4d
__VERBATIM(__FUNC_SIG("withdraw(uint256)"))
// __RIGHTPAD normally produces: 7f1234...000 (PUSH32 + 32 bytes)
// __VERBATIM strips the PUSH32, emitting just the 32 bytes
__VERBATIM(__RIGHTPAD(0x1234))
}
__BYTES(<string>|<string constant>)
This function converts a string to UTF-8 encoded bytes and inserts them into the compiled bytecode. The resulting bytecode is limited to 32 bytes.
You can pass either:
- A string literal directly:
__BYTES("hello") - A string constant reference:
__BYTES([GREETING])whereGREETINGis a string constant
Note: __BYTES only accepts string values. Hex constants are not allowed and will result in a compilation error.
Examples
Direct string literal:
#define macro MAIN() = takes (0) returns (0) {
__BYTES("hello") // Compiles to: PUSH5 0x68656c6c6f
}
String constant reference:
#define constant GREETING = "hello"
#define constant ERROR_MSG = "Unauthorized"
#define macro MAIN() = takes (0) returns (0) {
__BYTES([GREETING]) // Compiles to: PUSH5 0x68656c6c6f
__BYTES([ERROR_MSG]) // Compiles to: PUSH12 0x556e617574686f72697a6564
}
Chained __BYTES constants:
#define constant MSG = "test"
#define constant MSG_BYTES = __BYTES([MSG])
#define macro MAIN() = takes (0) returns (0) {
[MSG_BYTES] // Uses the pre-computed bytes
}
__ASSERT_PC(<literal>|<constant>)
This function is a compile-time assertion that validates the current bytecode position (program counter) matches the expected value. It generates no bytecode - it’s purely a compile-time check. If the assertion fails, compilation will stop with an error showing the expected vs actual position.
This is useful for ensuring critical instructions (like jump destinations) are positioned at specific bytecode offsets, which can be important for gas optimization or when interfacing with external systems that expect specific bytecode layouts.
Example
#define macro MAIN() = takes (0) returns (0) {
__ASSERT_PC(0x00) // Assert we're at the start
0x01 0x02 // PUSH1 0x01, PUSH1 0x02 = 4 bytes
__ASSERT_PC(0x04) // Assert we're at byte 4
target: // Label at position 0x04 (generates JUMPDEST = 1 byte)
__ASSERT_PC(0x05) // Assert we're at byte 5
0x11 // PUSH1 0x11 = 2 bytes
__ASSERT_PC(0x07) // Assert we're at byte 7
}
You can also use constants and combine with for-loops:
#define constant TARGET_OFFSET = 0x20
#define macro MAIN() = takes (0) returns (0) {
// Fill space to reach target offset using for-loop with constant
for(i in 0..[TARGET_OFFSET]) {
stop // Expands to 32 stop instructions = 32 bytes
}
__ASSERT_PC([TARGET_OFFSET]) // Ensure we're at the expected offset (0x20 = 32 bytes)
important_label: // Label generates JUMPDEST automatically
}
Combining Builtin Functions
Some builtin functions can be combined with other functions. Possible combinations are:
__RIGHTPAD(__FUNC_SIG("test(address, uint256)"))__RIGHTPAD(__BYTES("hello"))
Builtin Functions as Macro Arguments
Builtin functions that can be evaluated at compile-time can be passed as macro arguments. This allows for more flexible and reusable macro definitions.
The following builtin functions support being passed as macro arguments:
__FUNC_SIG- Function selectors__EVENT_HASH- Event hashes__BYTES- String bytes__RIGHTPAD- Right-padded values
Example
#define function transfer(address,uint256) nonpayable returns ()
#define macro PUSH_VALUE(val) = takes(0) returns(1) {
<val>
}
#define macro MAIN() = takes(0) returns(0) {
// Pass builtin function call as macro argument
PUSH_VALUE(__FUNC_SIG(transfer))
// Pass padded builtin as argument
PUSH_VALUE(__RIGHTPAD(0x1234))
// Pass bytes as argument
PUSH_VALUE(__BYTES("test"))
pop pop pop
}
This feature enables creating generic utility macros that work with computed values, improving code reusability and maintainability.
Example
// Define a function
#define function test1(address, uint256) nonpayable returns (bool)
#define function test2(address, uint256) nonpayable returns (bool)
// Define an event
#define event TestEvent1(address, uint256)
#define event TestEvent2(address, uint256)
#define macro TEST1() = takes (0) returns (0) {
0x00 0x00 // [address, uint]
__EVENT_HASH(TestEvent1) // [sig, address, uint]
0x00 0x00 // [mem_start, mem_end, sig, address, uint]
log3 // []
}
#define macro TEST2() = takes (0) returns (0) {
0x00 0x00 // [address, uint]
__EVENT_HASH(TestEvent2) // [sig, address, uint]
0x00 0x00 // [mem_start, mem_end, sig, address, uint]
log3 // []
}
#define macro MAIN() = takes (0) returns (0) {
// Identify which function is being called.
0x00 calldataload 0xE0 shr
dup1 __FUNC_SIG(test1) eq test1 jumpi
dup1 __FUNC_SIG(test2) eq test2 jumpi
// Revert if no function matches
0x00 0x00 revert
test1:
TEST1()
test2:
TEST2()
}
See Also
- Constants - Documentation for
FREE_STORAGE_POINTER(), a special compile-time function that allocates unique storage slots - Builtin Constants - Documentation for built-in constants like
__NOOP
Builtin Constants
Built-in constants are compiler-provided constants with special behavior during compilation. Unlike user-defined constants which resolve to literal values, built-in constants may generate specialized bytecode or no bytecode.
__NOOP
At compile time, __NOOP generates no bytecode. When the compiler encounters __NOOP, it skips code generation for that position.
Behavior
__NOOPcan appear in macro bodies, as macro arguments, in for loop bodies, and inside label definitions- When referenced through constants (
[CONST]), it generates no bytecode __NOOPis a reserved name and cannot be used for user-defined constants
Example: Basic Usage
#define macro EXAMPLE() = takes(0) returns(0) {
__NOOP // Generates: (nothing)
0x01 // Generates: PUSH1 0x01 = 6001
__NOOP // Generates: (nothing)
dup1 // Generates: DUP1 = 80
__NOOP // Generates: (nothing)
}
// Total bytecode: 600180
Example: As a Named Constant
#define constant NO_OP = __NOOP
#define macro MAIN() = takes(0) returns(0) {
[NO_OP] // Generates no bytecode
0x42 // Generates: PUSH1 0x42
}
Example: Conditional Code via Macro Arguments
#define macro OPTIONAL_LOG(value, should_log) = takes(0) returns(0) {
<should_log> // Expands to opcodes or __NOOP
<value>
}
#define macro MAIN() = takes(0) returns(0) {
// With logging
OPTIONAL_LOG(0xff, log0) // Generates: LOG0 PUSH1 0xff
// Without logging
OPTIONAL_LOG(0xff, __NOOP) // Generates: PUSH1 0xff
}
See Also
- Builtin Functions - Compile-time functions like
__FUNC_SIG()and__TABLESIZE() - Constants - User-defined constants and
FREE_STORAGE_POINTER() - Macros and Functions - How to use
__NOOPwith macro arguments
Define functions and events
While defining an interface is not a necessary step, functions and events
can be defined in Huff contracts for two purposes: To be used as arguments
for the __FUNC_SIG and __EVENT_HASH builtins, and to generate a Solidity
Interface / Contract ABI.
Functions can be of type view, pure, payable or nonpayable, and
function interfaces should only be defined for externally facing functions.
Events can contain indexed and non-indexed values.
Example
Define a function:
#define function testFunction(uint256, bytes32) view returns (bytes memory)
Define an event:
#define event TestEvent(address indexed, uint256)
Constants
Constants in Huff contracts are not included in the contract’s storage; Instead,
they are able to be called within the contract at compile time. Constants
can be bytes (32 max), string literals, FREE_STORAGE_POINTER, a built-in function, or an arithmetic expression.
A FREE_STORAGE_POINTER constant will always represent an unused storage slot in the contract.
In order to push a constant to the stack, use bracket notation: [CONSTANT]
Example
Constant Declaration
#define constant NUM = 0x420
#define constant HELLO_WORLD = 0x48656c6c6f2c20576f726c6421
#define constant GREETING = "hello"
#define constant FREE_STORAGE = FREE_STORAGE_POINTER()
#define constant TEST = __FUNC_SIG("test(uint256)")
Constant Usage
(without loss of generality, let’s say the constant NUM holds 0x420 from the above example)
// [] - an empty stack
[NUM] // [0x420] - the constant's value is pushed to the stack
Arithmetic Expressions
Constants can use arithmetic expressions evaluated at compile time.
Supported Operators
Binary Operators:
+Addition-Subtraction*Multiplication/Division (integer)%Modulo
Unary Operators:
-Negation
Operator Precedence
Operators follow standard mathematical precedence:
- Unary negation (
-), parentheses() - Multiplication (
*), Division (/), Modulo (%) - left-associative - Addition (
+), Subtraction (-) - left-associative
Use parentheses to override precedence.
Examples
Basic Arithmetic:
#define constant BASE = 0x20
#define constant OFFSET = 0x04
#define constant COMBINED = [BASE] + [OFFSET] // Result: 0x24
#define constant TEN = 0x0a
#define constant FIVE = 0x05
#define constant SIMPLE_ADD = [TEN] + [FIVE] // Result: 0x0f
#define constant SIMPLE_SUB = [TEN] - [FIVE] // Result: 0x05
#define constant MULTIPLY = 0x03 * 0x04 // Result: 0x0c
#define constant DIVIDE = 0x10 / 0x02 // Result: 0x08
#define constant MODULO = 0x0a % 0x03 // Result: 0x01
Complex Expressions:
#define constant COMPLEX = ([TEN] + [FIVE]) * 0x02 // Result: 0x1e (30 in decimal)
#define constant NESTED = [BASE] + ([OFFSET] * 0x02) // Result: 0x28
// Precedence: multiplication before addition
#define constant PRECEDENCE = 0x02 + 0x03 * 0x04 // Result: 0x0e (2 + 12)
// Left-associative operations
#define constant CHAIN = 0x10 - 0x05 - 0x02 // Result: 0x09 ((16 - 5) - 2)
Negation:
#define constant POSITIVE = 0x0a
#define constant NEGATIVE = -[POSITIVE] // Result: 0xfffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff6
// Negation in expressions
#define constant MIXED = -0x05 + 0x0a // Result: 0x05
Use Cases
Storage Slots:
#define constant STORAGE_SLOT_0 = 0x00
#define constant STORAGE_SLOT_1 = [STORAGE_SLOT_0] + 0x01
#define constant STORAGE_SLOT_2 = [STORAGE_SLOT_0] + 0x02
Memory Offsets:
#define constant MEM_OFFSET_0 = 0x00
#define constant MEM_OFFSET_32 = [MEM_OFFSET_0] + 0x20
#define constant MEM_OFFSET_64 = [MEM_OFFSET_32] + 0x20
Size Computations:
#define constant WORD_SIZE = 0x20
#define constant HALF_WORD = [WORD_SIZE] / 0x02
#define constant DOUBLE_WORD = [WORD_SIZE] * 0x02
ABI Encoding:
#define constant SELECTOR_SIZE = 0x04
#define constant FIRST_ARG_OFFSET = SELECTOR_SIZE
#define constant SECOND_ARG_OFFSET = [SELECTOR_SIZE] + 0x20
Compile-Time Evaluation
Expressions are evaluated during compilation. The compiler replaces the expression with the computed value and generates a single PUSH instruction. Constants must be defined before use.
#define constant A = 0x10
#define constant B = 0x05
#define constant C = [A] + [B] // Evaluated to 0x15 at compile time
#define macro EXAMPLE() = takes(0) returns(0) {
[C] // Compiles to: PUSH1 0x15
}
String Literals
String literal constants can be defined using double quotes. String constants cannot be pushed to the stack directly - they must be converted to bytes using the __BYTES builtin function.
String Constant Declaration
#define constant GREETING = "hello"
#define constant MESSAGE = "transfer(address,uint256)"
String Constant Usage
String constants must be used with the __BYTES builtin function, which converts the string to UTF-8 encoded bytes:
#define constant GREETING = "hello"
#define macro MAIN() = takes(0) returns(0) {
__BYTES([GREETING]) // Compiles to: PUSH5 0x68656c6c6f
}
Direct usage is not allowed:
// ❌ ERROR: String constants cannot be pushed directly
#define constant MSG = "hello"
#define macro EXAMPLE() = takes(0) returns(0) {
[MSG] // Compilation error: use __BYTES([MSG]) instead
}
Use Cases
Function Signatures:
#define constant TRANSFER_SIG = "transfer(address,uint256)"
#define macro GET_SELECTOR() = takes(0) returns(1) {
__BYTES([TRANSFER_SIG]) // Push signature as bytes
}
Error Messages (limited to 32 bytes):
#define constant ERROR_MSG = "Insufficient balance"
#define macro REVERT_WITH_MSG() = takes(0) returns(0) {
__BYTES([ERROR_MSG])
0x00 mstore
0x20 0x00 revert
}
Combining with Other Builtins:
#define constant GREETING = "hi"
#define macro EXAMPLE() = takes(0) returns(0) {
// String bytes can be padded
__RIGHTPAD(__BYTES([GREETING])) // Right-pad the UTF-8 bytes
}
Compile-Time Loops
Huff Neo supports compile-time for loops that expand during compilation, allowing you to generate repetitive code patterns without manual duplication.
Syntax
for(variable in start..end) {
// loop body
}
for(variable in start..end step N) {
// loop body with custom step
}
Features
- Compile-time expansion: Loops are expanded during compilation and don’t exist in the final bytecode
- Variable interpolation: Use
<variable>to insert the current iteration value as a literal - Constant expressions: Loop bounds can use constants and arithmetic
- Nested loops: Loops can be nested within each other
Basic Usage
Simple Repetition
Generate a sequence of literal values:
#define macro PUSH_SEQUENCE() = takes(0) returns(3) {
for(i in 0..3) {
<i>
}
// Expands to: 0x00 0x01 0x02
}
With Opcodes
Use loop variables with explicit opcodes:
#define macro PUSH_VALUES() = takes(0) returns(3) {
for(i in 1..4) {
push1 <i>
}
// Expands to: push1 0x01 push1 0x02 push1 0x03
}
Custom Step
Use a step value other than 1:
#define macro EVEN_NUMBERS() = takes(0) returns(5) {
for(i in 0..10 step 2) {
<i>
}
// Expands to: 0x00 0x02 0x04 0x06 0x08
}
Variable Interpolation
The <variable> syntax inserts the current iteration value as a hex literal (matching Huff’s existing <arg> syntax for macro arguments):
for(i in 0..3) {
<i> // Becomes: 0x00, then 0x01, then 0x02
}
Note: Loop variables shadow macro arguments. Inside a for loop, <i> always refers to the loop variable, even if there’s a macro argument with the same name.
Limitations
<variable>only works as a literal value- Cannot interpolate into identifiers or label names
- Cannot use variable in constant names
Supported:
for(i in 0..3) {
<i> // ✓ Literal value
push1 <i> // ✓ Literal after opcode
}
Not Supported:
for(i in 0..3) {
[SLOT_<i>] // ✗ No interpolation in identifiers
label_<i>: // ✗ No interpolation in labels
}
Loop Bounds
Loop bounds must be constant expressions that can be evaluated at compile-time.
Constant References
When referencing constants in loop bounds or step values, you must use bracket notation [CONSTANT_NAME]:
#define constant END = 10
// ✓ Correct - bracket notation required
for(i in 0..[END]) { }
// ✗ Incorrect - bare constant name not allowed
for(i in 0..END) { }
This applies to all positions where constants appear:
- Start bound:
for(i in [START]..end) - End bound:
for(i in start..[END]) - Step value:
for(i in start..end step [STEP])
U256 Range Support
Loop ranges support full u256 values using hex notation:
#define constant START = 0x00
#define constant END = 0xFF
#define constant STEP = 0x10
#define macro USE_CONSTANTS() = takes(0) returns(16) {
for(i in [START]..[END] step [STEP]) {
<i>
}
}
You can use hex literals directly:
for(i in 0x00..0x100 step 0x20) {
<i>
}
// Works with any u256 value up to 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
Arithmetic in Bounds
You can use arithmetic expressions:
#define constant SIZE = 5
for(i in 0..[SIZE] * 2) {
<i>
}
// Expands iterations from 0 to 9
Macro Arguments in Bounds
Macro arguments can be used in loop bounds using <arg> syntax. The arguments are evaluated at compile-time during macro expansion.
Basic Usage
#define macro LOOP(count) = takes(0) returns(0) {
for(i in 0..<count>) {
<i>
}
}
#define macro MAIN() = takes(0) returns(0) {
LOOP(0x03) // Expands to: 0x00 0x01 0x02
}
With Start and End Arguments
#define macro RANGE(start, end) = takes(0) returns(0) {
for(i in <start>..<end>) {
<i>
}
}
#define macro MAIN() = takes(0) returns(0) {
RANGE(0x05, 0x08) // Expands to: 0x05 0x06 0x07
}
With Step Argument
#define macro STEPPED(count, step) = takes(0) returns(0) {
for(i in 0..<count> step <step>) {
<i>
}
}
#define macro MAIN() = takes(0) returns(0) {
STEPPED(0x0A, 0x02) // Expands to: 0x00 0x02 0x04 0x06 0x08
}
With Arithmetic
Arguments can be used in arithmetic expressions:
#define macro COMPUTED(base, extra) = takes(0) returns(0) {
for(i in 0..(<base> + <extra>)) {
<i>
}
}
#define macro MAIN() = takes(0) returns(0) {
COMPUTED(0x02, 0x03) // Loop from 0 to 5
}
Mixed with Constants
Arguments can be combined with constants in bound expressions:
#define constant BASE = 0x10
#define macro ADD_RANGE(offset) = takes(0) returns(0) {
for(i in [BASE]..([BASE] + <offset>)) {
<i>
}
}
#define macro MAIN() = takes(0) returns(0) {
ADD_RANGE(0x05) // Loop from 0x10 to 0x15
}
Iteration Limit
Important: To prevent compile-time explosion and excessive bytecode generation, loops are limited to 10,000 iterations maximum.
If your loop exceeds this limit, you’ll get a compile error:
// This will error - exceeds 10,000 iterations
for(i in 0..0x10000) { // 65,536 iterations
<i>
}
This safety limit prevents:
- Runaway compilation times
- Out-of-memory errors
- Accidentally generating massive bytecode
Nested Loops
Loops can be nested for multi-dimensional patterns:
#define macro NESTED_EXAMPLE() = takes(0) returns(0) {
for(i in 0..2) {
for(j in 0..2) {
// Both i and j are available
<i>
<j>
}
}
// Expands to: 0x00 0x00 0x00 0x01 0x01 0x00 0x01 0x01
}
Common Use Cases
Initialize Storage Slots
#define macro INIT_STORAGE() = takes(0) returns(0) {
for(slot in 0..10) {
0x00 <slot> sstore // Store zero at each slot
}
}
Generate Function Selector Table
#define macro SELECTOR_TABLE() = takes(0) returns(0) {
for(idx in 0..5) {
dup1
<idx>
eq
handler jumpi
}
}
Unroll Loops for Gas Optimization
Instead of runtime loops, unroll them at compile-time:
// Runtime loop (more gas per iteration)
loop:
// ...
loop jumpi
// Compile-time loop (no runtime overhead)
for(i in 0..[COUNT]) {
// ... unrolled code
}
Technical Notes
- Loop bounds are inclusive of
start, exclusive ofend(like Rust ranges) - Default step is 1 if not specified
- Step must not be zero (compile error)
- Labels inside loop bodies are automatically renamed to prevent conflicts
- Maximum iteration count limited by reasonable compile-time bounds
Examples
Matrix Operation
#define constant MATRIX_SIZE = 4
#define macro INIT_MATRIX() = takes(0) returns(0) {
for(row in 0..[MATRIX_SIZE]) {
for(col in 0..[MATRIX_SIZE]) {
0x00
<row>
<col>
add
sstore
}
}
}
Optimized Array Copy
#define constant ARRAY_LENGTH = 32
#define macro COPY_ARRAY() = takes(2) returns(0) {
// Takes: source_ptr dest_ptr
for(offset in 0..[ARRAY_LENGTH] step 0x20) {
// Load from source
dup2 <offset> add mload
// Store to dest
dup2 <offset> add mstore
}
pop pop
}
Compile-Time Conditionals
Huff Neo supports compile-time if, else if, and else statements that expand during compilation. Conditions are evaluated at compile-time, and only the matching branch is included in the final bytecode.
Syntax
if (condition) {
// statements
}
if (condition) {
// statements
} else {
// statements
}
if (condition) {
// statements
} else if (condition2) {
// statements
} else {
// statements
}
Features
- Compile-time expansion: Statements are expanded during compilation and don’t exist in the final bytecode
- Constant expressions: Conditions must be constant expressions
- Comparison operators:
==,!=,<,>,<=,>= - Logical NOT:
!operator - Nested conditionals: If statements can be nested
Basic Usage
Simple If
#define constant ENABLED = 0x01
#define macro MAIN() = takes(0) returns(0) {
if ([ENABLED]) {
0x42 0x00 mstore
}
// Expands to: 0x42 0x00 mstore
}
If/Else
#define constant MODE = 0x00
#define macro MAIN() = takes(0) returns(0) {
if ([MODE]) {
0xAA
} else {
0xBB
}
// Expands to: 0xBB
}
If/Else If Chain
#define constant VALUE = 0x02
#define macro MAIN() = takes(0) returns(0) {
if ([VALUE] == 0x01) {
0x11
} else if ([VALUE] == 0x02) {
0x22
} else {
0x33
}
// Expands to: 0x22
}
Comparison Operators
Comparison operators return 1 for true, 0 for false.
Equality
#define constant A = 0x05
#define constant B = 0x05
if ([A] == [B]) { } // true
if ([A] != [B]) { } // false
Relational
#define constant X = 0x0A
#define constant Y = 0x05
if ([X] > [Y]) { } // true (10 > 5)
if ([X] < [Y]) { } // false
if ([X] >= [Y]) { } // true
if ([X] <= [Y]) { } // false
Logical NOT
The ! operator returns 1 if the operand is zero, 0 otherwise.
#define constant DEBUG = 0x00
if (![DEBUG]) {
// Expands (DEBUG is zero, !0 = 1)
0xFF
}
Arithmetic in Conditions
#define constant A = 0x10
#define constant B = 0x20
#define constant THRESHOLD = 0x05
#define macro CHECK() = takes(0) returns(0) {
if ([A] + [B] > [THRESHOLD]) {
0xFF
}
// Expands to: 0xFF (0x30 > 0x05)
}
With Parentheses
#define constant A = 0x02
#define constant B = 0x03
#define constant C = 0x04
if (([A] + [B]) * [C] > 0x10) {
// ((2 + 3) * 4) > 16
// 20 > 16 = true
}
Operator Precedence
Operators follow this precedence (highest to lowest):
- Parentheses:
( ) - Unary:
-,! - Multiplicative:
*,/,% - Additive:
+,- - Comparison:
==,!=,<,>,<=,>=
Example:
if ([A] + [B] * [C] > [D]) {
// Evaluated as: (A + (B * C)) > D
}
Nested Conditionals
#define constant OUTER = 0x01
#define constant INNER = 0x00
#define macro NESTED() = takes(0) returns(0) {
if ([OUTER]) {
if ([INNER]) {
0xAA
} else {
0xBB
}
} else {
0xCC
}
// Expands to: 0xBB
}
Constant References
When referencing constants in conditions, use bracket notation [CONSTANT_NAME]:
#define constant FLAG = 0x01
// ✓ Correct
if ([FLAG]) { }
if ([FLAG] == 0x01) { }
// ✗ Incorrect
if (FLAG) { }
This follows the Huff language convention for constant values.
Macro Arguments in Conditions
Macro arguments can be used in if conditions using <arg> syntax. The arguments are evaluated at compile-time during macro expansion.
Basic Usage
#define macro CHECK(threshold) = takes(0) returns(0) {
if (<threshold>) {
0x42
} else {
0x10
}
}
#define macro MAIN() = takes(0) returns(0) {
CHECK(0x01) // Expands to: 0x42
}
With Comparisons
#define macro VALIDATE(value, max) = takes(0) returns(0) {
if (<value> <= <max>) {
0xFF // Valid
} else {
0x00 // Invalid
}
}
#define macro MAIN() = takes(0) returns(0) {
VALIDATE(0x05, 0x0A) // Expands to: 0xFF
}
With Arithmetic
#define macro COMPUTE(a, b) = takes(0) returns(0) {
if (<a> + <b> > 0x10) {
0xAA
} else {
0xBB
}
}
#define macro MAIN() = takes(0) returns(0) {
COMPUTE(0x08, 0x0C) // 0x08 + 0x0C = 0x14 > 0x10
// Expands to: 0xAA
}
Mixed with Constants
Arguments can be combined with constants in expressions:
#define constant BASE = 0x10
#define macro ADD_OFFSET(offset) = takes(0) returns(0) {
if ([BASE] + <offset> > 0x20) {
0x01
} else {
0x00
}
}
#define macro MAIN() = takes(0) returns(0) {
ADD_OFFSET(0x15) // 0x10 + 0x15 = 0x25 > 0x20
// Expands to: 0x01
}
Use Cases
Feature Flags
#define constant ENABLE_LOGGING = 0x01
#define macro PROCESS() = takes(0) returns(0) {
if ([ENABLE_LOGGING]) {
__EVENT_HASH("Processed()")
0x00 0x00 log0
}
}
Configuration-Based Generation
#define constant NETWORK = 0x01 // mainnet=1, testnet=2
#define macro GET_CHAIN_ID() = takes(0) returns(1) {
if ([NETWORK] == 0x01) {
0x01 // Mainnet chain ID
} else if ([NETWORK] == 0x02) {
0x05 // Goerli chain ID
} else {
0x7a69 // Local chain ID
}
}
Build Variants
#define constant DEBUG = 0x00
#define macro MAIN() = takes(0) returns(0) {
if ([DEBUG]) {
__EVENT_HASH("Debug:Entry()")
0x00 0x00 log0
}
PROCESS()
if ([DEBUG]) {
__EVENT_HASH("Debug:Exit()")
0x00 0x00 log0
}
}
Limitations
Constant Expressions Only
Conditions must be evaluable at compile-time:
// ✓ Valid
if ([CONSTANT] > 5) { }
// ✗ Invalid - runtime value
if (calldataload(0x00) > 5) { }
Label Scoping
Labels in one branch cannot be referenced from another:
// ✗ Invalid
if ([FLAG]) {
success:
0x01
} else {
success jump // Error: success not visible
}
No Side Effects
Conditions are pure expressions:
// ✗ Invalid
if (some_macro()) { }
Comparison with Runtime Branching
Compile-Time (if/else)
- Conditions evaluated during compilation
- Only matching branch in bytecode
- No runtime cost
- Cannot use runtime values
if ([CONSTANT] > 5) { }
Runtime (jumpi)
- Conditions evaluated during execution
- All branches in bytecode
- Runtime gas cost
- Can use any stack values
dup1 0x05 gt
success jumpi
// failure branch
success:
// success branch
Technical Notes
- Conditions are evaluated during the expansion phase before bytecode generation
- Non-zero values are true, zero is false
- Conditions use constant folding for evaluation
- Labels follow normal scoping rules within branches
Examples
Multi-Level Configuration
#define constant ENV = 0x01 // 1=prod, 2=staging, 3=dev
#define macro MAIN() = takes(0) returns(0) {
if ([ENV] == 0x01) {
STRICT_VALIDATE()
} else if ([ENV] == 0x02) {
MEDIUM_VALIDATE()
} else {
DEBUG_LOG()
}
CORE_LOGIC()
}
Conditional Loop Unrolling
#define constant SIZE = 0x04
#define macro PROCESS() = takes(0) returns(0) {
if ([SIZE] <= 0x04) {
// Unroll small loops
PROCESS_ITEM(0x00)
PROCESS_ITEM(0x01)
PROCESS_ITEM(0x02)
PROCESS_ITEM(0x03)
} else {
// Use runtime loop for larger sizes
for(i in 0..[SIZE]) {
PROCESS_ITEM(<i>)
}
}
}
Custom Errors
Custom errors can be defined and used by the __ERROR builtin to push the left-padded 4 byte
error selector to the stack.
Example
// Define our custom error
#define error PanicError(uint256)
#define error Error(string)
#define macro PANIC() = takes (1) returns (0) {
// Input stack: [panic_code]
__ERROR(PanicError) // [panic_error_selector, panic_code]
0x00 mstore // [panic_code]
0x04 mstore // []
0x24 0x00 revert
}
#define macro REQUIRE() = takes (3) returns (0) {
// Input stack: [condition, message_length, message]
continue jumpi // [message_length, message]
__ERROR(Error) // [error_selector, message_length, message]
0x00 mstore // [message_length, message]
0x20 0x04 mstore // [message_length, message]
0x24 mstore // [message]
0x44 mstore // []
0x64 0x00 revert
continue:
pop // []
}
Jump Labels
Jump Labels are a simple abstraction included into the language to make defining
and referring to JUMPDESTs more simple for the developer.
Example
#define macro MAIN() = takes (0) returns (0) {
// Store "Hello, World!" in memory
0x48656c6c6f2c20576f726c6421
0x00 mstore // ["Hello, World!"]
// Jump to success label, skipping the revert statement
success // [success_label_pc, "Hello, World!"]
jump // ["Hello, World!"]
// Revert if this point is reached
0x00 0x00 revert
// Labels are defined within macros or functions, and are designated
// by a word followed by a colon. Note that while it may appear as if
// labels are scoped code blocks due to the indentation, they are simply
// destinations to jump to in the bytecode. If operations exist below a label,
// they will be executed unless the program counter is altered or execution is
// halted by a `revert`, `return`, `stop`, or `selfdestruct` opcode.
success:
0x00 mstore
0x20 0x00 return
}
Label Scoping
Huff-Neo implements scoped label resolution to prevent situations where multiple macro invocations defining the same label would cause all jumps to incorrectly target the last definition.
Scoping Rules
Label Definition
- Each label is associated with the scope where it’s defined
- A scope is determined by the macro invocation chain
- Labels defined directly in a macro belong to that macro’s scope
- Labels defined in invoked macros belong to the invoked macro’s scope
Duplicate Detection
- Within Same Scope: Duplicate labels in the same scope will cause a compilation error
- Across Different Scopes: Labels with the same name in different scopes are allowed (shadowing)
Label Resolution
Labels are resolved in the following order:
- Current and Parent Scopes: Searches from the current scope upward through parent scopes
- Child Scopes: If not found, searches in child scopes (macros invoked from current scope)
- Sibling Scopes: As a fallback, searches in sibling scopes (macros invoked from the same parent)
This resolution order allows:
- Inner scope labels to shadow outer scope labels
- Parent macros to reference labels defined in nested child macros
- Sibling macros to cross-reference each other’s labels when needed
Examples
Duplicate Labels (Error)
#define macro MAIN() = takes(0) returns(0) {
my_label: // First definition
0x01
my_label: // ERROR: Duplicate label in same scope
0x02
}
Label Shadowing (Allowed)
#define macro INNER() = takes(0) returns(0) {
my_label: // Label in INNER scope
0x01
my_label // Jumps to INNER's my_label
}
#define macro MAIN() = takes(0) returns(0) {
my_label: // Label in MAIN scope
0x00
INNER() // INNER has its own my_label
my_label // Jumps to MAIN's my_label
}
Multiple Macro Invocations
#define macro DEF_LBL() = takes(0) returns(0) {
my_label:
0x42
my_label // Jumps to THIS invocation's my_label
}
#define macro MAIN() = takes(0) returns(0) {
DEF_LBL() // First invocation - creates my_label in its scope
DEF_LBL() // Second invocation - creates my_label in its own scope
// Both invocations work correctly with their own labels
}
Parent Accessing Child Labels
#define macro INNER() = takes(0) returns(0) {
inner_label: // Label defined in nested macro
0x42
}
#define macro OUTER() = takes(0) returns(0) {
INNER() // Invoke macro that defines inner_label
}
#define macro MAIN() = takes(0) returns(0) {
OUTER()
inner_label jump // Parent can jump to label in nested child
}
Sibling Cross-References
#define macro FIRST() = takes(0) returns(0) {
first_label:
0x01
}
#define macro SECOND() = takes(0) returns(0) {
first_label jump // Can reference sibling's label
}
#define macro MAIN() = takes(0) returns(0) {
FIRST() // Defines first_label
SECOND() // References first_label from FIRST
}
Labels as Macro Arguments
When labels are passed as arguments to macros, they are resolved from the perspective of the macro that’s passing them, not the macro that’s using them. This allows labels to be accessed across different scopes:
#define macro SET_LABEL() = takes(0) returns(0) {
my_label:
0x42
}
#define macro USE_LABEL(lbl) = takes(0) returns(0) {
<lbl> jump // Uses the label passed as argument
}
#define macro WRAPPER(m) = takes(0) returns(0) {
USE_LABEL(<m>) // Pass label as argument to USE_LABEL
}
#define macro MAIN() = takes(0) returns(0) {
SET_LABEL() // Define my_label in SET_LABEL's scope
WRAPPER(my_label) // Pass label through nested invocations
}
In this example:
my_labelis defined inSET_LABEL’s scope (a child of MAIN)- When
MAINcallsWRAPPER(my_label), the label is resolved from MAIN’s perspective - MAIN can see
my_labelbecause it’s defined in a child scope (SET_LABEL) WRAPPERpasses the label toUSE_LABELas<m>- When
USE_LABELuses<lbl>, it jumps to the correct label
This works even with deeply nested invocations:
#define macro DEEP_USE(label) = takes(0) returns(0) {
<label> jump
}
#define macro LEVEL2(lbl) = takes(0) returns(0) {
DEEP_USE(<lbl>) // Pass through another level
}
#define macro LEVEL1(l) = takes(0) returns(0) {
LEVEL2(<l>) // Pass through to LEVEL2
}
#define macro MAIN() = takes(0) returns(0) {
target:
0x42
LEVEL1(target) // Label resolved from MAIN's scope
}
The key point is that label arguments (<label>) are resolved where they are passed, not where they are used. This enables flexible label passing between macros at different scope levels.
Label Shadowing with Arguments
When passing labels as arguments, shadowing rules still apply. Inner scope labels shadow outer scope labels:
#define macro USE_LABEL(lbl) = takes(0) returns(0) {
<lbl> jump
}
#define macro INNER() = takes(0) returns(0) {
target: // Inner scope's target
0x01
USE_LABEL(target) // Resolves to INNER's target (0x01)
}
#define macro MAIN() = takes(0) returns(0) {
target: // MAIN's target
0x00
INNER() // INNER defines its own target
USE_LABEL(target) // Resolves to MAIN's target (0x00)
}
In this example:
INNERdefines its owntargetlabel that shadowsMAIN’starget- When
INNERpassestargettoUSE_LABEL, it resolves to INNER’s label - When
MAINpassestargettoUSE_LABEL, it resolves to MAIN’s label - Each macro sees and passes its own version of the label
This shadowing behavior is useful when you want macros to work with their local labels without worrying about naming conflicts:
#define macro JUMP_TO(lbl) = takes(0) returns(0) {
<lbl> jump
}
#define macro PROCESS() = takes(0) returns(0) {
loop: // Local loop label
0x01 add
dup1 0x10 lt
loop JUMP_TO // Uses local loop, not affected by other loops
}
#define macro MAIN() = takes(0) returns(0) {
loop: // MAIN's loop label
PROCESS() // PROCESS has its own loop
loop jump // Jumps to MAIN's loop
}
Best Practices
- Use unique label names within a macro to avoid confusion
- Be aware that macro invocations create new scopes
- Use label shadowing intentionally and document it when used
- Consider prefixing labels with macro names for clarity in complex contracts
Jump Tables
Jump Tables are a convenient way to create switch cases in your Huff contracts. Each jump table consists of jumpdest program counters (PCs), and it is written to your contract’s bytecode. These jumpdest PCs can be codecopied into memory, and the case can be chosen by finding a jumpdest at a particular memory pointer (i.e. 0x00 = case 1, 0x20 = case 2, etc.). This allows for a single jump rather than many conditional jumps.
There are two different kinds of Jump Tables in Huff: Regular and
Packed. Regular Jump Tables store jumpdest PCs as full 32 byte
words, and packed Jump Tables store them each as 2 bytes. Therefore,
packed jumptables are cheaper to copy into memory, but they are more
expensive to pull a PC out of due to the bitshifting required. The
opposite is true for Regular Jump Tables.
There are two builtin functions related to jumptables.
__tablestart(TABLE)
Pushes the program counter (PC) of the start of the table passed to the stack.
__tablesize(TABLE)
Pushes the code size of the table passed to the stack.
Example
// Define a function
#define function switchTest(uint256) pure returns (uint256)
// Define a jump table containing 4 pcs
#define jumptable SWITCH_TABLE {
jump_one jump_two jump_three jump_four
}
#define macro SWITCH_TEST() = takes (0) returns (0) {
// Codecopy jump table into memory @ 0x00
__tablesize(SWITCH_TABLE) // [table_size]
__tablestart(SWITCH_TABLE) // [table_start, table_size]
0x00
codecopy
0x04 calldataload // [input_num]
// Revert if input_num is not in the bounds of [0, 3]
dup1 // [input_num, input_num]
0x03 lt // [3 < input_num, input_num]
err jumpi
// Regular jumptables store the jumpdest PCs as full words,
// so we simply multiply the input number by 32 to determine
// which label to jump to.
0x20 mul // [0x20 * input_num]
mload // [pc]
jump // []
jump_one:
0x100 0x00 mstore
0x20 0x00 return
jump_two:
0x200 0x00 mstore
0x20 0x00 return
jump_three:
0x300 0x00 mstore
0x20 0x00 return
jump_four:
0x400 0x00 mstore
0x20 0x00 return
err:
0x00 0x00 revert
}
#define macro MAIN() = takes (0) returns (0) {
// Identify which function is being called.
0x00 calldataload 0xE0 shr
dup1 __FUNC_SIG(switchTest) eq switch_test jumpi
// Revert if no function matches
0x00 0x00 revert
switch_test:
SWITCH_TEST()
}
Code Tables
Code Tables contain raw bytecode. The compiler places the code within them at the end of the runtime bytecode, assuming they are referenced somewhere within the contract.
Example
Define a code table
#define table CODE_TABLE {
0x604260005260206000F3
}
#define macro MAIN() = takes (0) returns (0) {
// Copy the code table into memory at 0x00
__tablesize(CODE_TABLE) // size
__tablestart(CODE_TABLE) // offset
0x00 // destOffset
codecopy
}
Usage of a builtin function
#define table CODE_TABLE {
__RIGHTPAD(__FUNC_SIG("test(address, uint256)"))
0x604260005260206000F3
}
Usage of a constant reference
#define constant CONST = 0x123
#define table CODE_TABLE {
[CONST]
__LEFTPAD([CONST])
}
Usage of builtin function constants
#define constant SIG = __FUNC_SIG("transfer(address,uint256)")
#define constant PADDED = __RIGHTPAD(0x42)
#define table CODE_TABLE {
[SIG] // Function selector from constant
[PADDED] // Padded value from constant
}
This is particularly useful when you want to reuse computed builtin values in multiple places, including both code and data tables.
Tests
The compiler includes a simple, stripped-down testing framework to assist in creating assertions
as well as gas profiling macros and functions. huff-rs’ test suite is intentionally lacking in features,
and with that, this addition is not meant to replace developers’ dependency on foundry-huff. Ideally,
for contracts that will be in production, Huff developers will utilize both foundry and Huff tests.
If you are one of many who uses Huff as a tool for learning, Huff tests can also be a lighter weight
experience when testing your contract’s logic.
Tests can be run via the CLI’s test subcommand. For more information, see the CLI Resources.
Decorators
The transaction environment for each test can be modified with a decorator. Decorators sit directly above
tests, and are formatted as follows: #[flag_a(inputs...), flag_b(inputs...)]
Available decorators include:
calldata- Set the calldata for the transaction environment. Accepts a single string of calldata bytes.value- Set the callvalue for the transaction environment. Accepts a single literal.
Example
#include "huffmate/utils/Errors.huff"
#define macro ADD_TWO() = takes (2) returns (1) {
// Input Stack: [a, b]
add // [a + b]
// Return Stack: [a + b]
}
#[calldata("0x0000000000000000000000000000000000000000000000000000000000000001"), value(0x01)]
#define test MY_TEST() = {
0x00 calldataload // [0x01]
callvalue // [0x01, 0x01]
eq ASSERT()
}
Overview
Introduction
Welcome to our beginner’s tutorial for smart contract developers interested in learning more about the Ethereum Virtual Machine (EVM). This tutorial is aimed towards developers who are already familiar with smart contracts and have had some experience programming in a smart contract language such as Solidity or Vyper.
In this tutorial, we’ll be covering:
- The basics of the Ethereum Virtual Machine
- The basics of writing assembly in Huff
- “Hello, World! in assembly
- Simple Storage in assembly
- Setting up a Foundry environment to write, test, and deploy your code
- Deploying your contracts to various Ethereum testnets
This tutorial loosely follows the original Hardhat tutorial.
To follow this tutorial you must:
- Be proficient in Solidity/Vyper.
- Understand how smart contracts work.
- Be competent using git.
- Have at least read the Foundry docs or developed contracts with it.
The Basics
Installation
Before you get started writing Huff you will have to install the compiler. Head over to Getting Started and follow the steps to get it installed. Once complete - come back here!!
What you are going to learn?
Unlike other programming languages, creating a Huff contract that returns “Hello, world!” is quite advanced! To keep things simple we are going to learn how to create a Huff contract that adds two numbers (then we will dive into “Hello, world!”).
Open up your editor and create a file called addTwo.huff. Lets jump in.
Add Two
ABI declaration
First things first. If you’re coming from a higher level language like Solidity or Vyper you will be familiar with defining “external” or “public” functions. These allow you to interact with a contract externally by generating an ABI (Application Binary Interface). This describes a contract’s entry points to external tools (We will dive more into this later). In this aspect Huff is exactly the same, you can declare functions that will appear in the abi at the top of the file.
#define function addTwo(uint256, uint256) view returns(uint256)
Go ahead and paste the above example at the top of addTwo.huff. This declares a function that takes two uint256 inputs and returns a single uint256.
The Main Macro
The next thing we are going to create is the MAIN macro. This serves a single entry point for Huff contracts. All calls to a contract (regardless of what function they are calling) will start from MAIN! In this example we will define a MAIN function that will read two uint256’s from calldata and return their result.
#define macro MAIN() = takes(0) returns(0) {
0x00 calldataload // [number1] // load first 32 bytes onto the stack - number 1
0x20 calldataload // [number2] // load second 32 bytes onto the stack - number 2
add // [number1+number2] // add number 1 and 2 and put the result onto the stack
0x00 mstore // place [number1 + number2] in memory
0x20 0x00 return // return the result
}
Looking at the above snippet may be intimidating at first, but bear with us.
You’ll notice that the MAIN directive is annotated with takes(0) returns(0). As the EVM is a stack based virtual machine (see: Understanding the EVM), all macro declarations are annotated with the number of items they will take from the stack and the amount they will return upon completion. When entering the contract the stack will be empty. Upon completion we will not be leaving anything on the stack; therefore, takes and returns will both be 0.
Go ahead and copy the above macro into your addTwo.huff file. Run hnc addTwo.huff --bytecode.
Congratulations you’ve just compiled your first contract!
The bytecode output of the compiler will echo the following into the console 600c8060093d393df35f35602035015f5260205ff3%.
When you deploy this contract code it will have the runtime bytecode of the main macro we just created! In the above snippet you will find it after the first f3 (the preceding bytecode is boilerplate constructor logic.)
That leaves us with this: 5f35602035015f5260205ff3
Below, this example dissembles what you have just created!
BYTECODE MNEMONIC STACK ACTION
5f // PUSH0 // [0x00]
35 // CALLDATALOAD // [number1] Store the first 32 bytes on the stack
60 20 // PUSH1 0x20 // [0x20, number1]
35 // CALLDATALOAD // [number2, number1] Store the second 32 bytes on the stack
01 // ADD // [number2 + number1] Take two stack inputs and add the result
5f // PUSH0 // [0x0, (n2 + n1)]
52 // MSTORE // [] Store (n2+n1) in the first 32 bytes of memory
60 20 // PUSH1 0x20 // [0x20]
f5 // PUSH0 // [0x00, 0x20]
f3 // RETURN // [] Return the first 32 bytes of memory
If you want to step through the execution yourself you can check out this snippet interactively in evm.codes (pass in the calldata 0x00000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000000002 and click RUN to get started). This calldata is the numbers 1 and 2, both padded to 32 bytes. After running this snippet, you should end up with a return value of 0000000000000000000000000000000000000000000000000000000000000003. Which is expected! addTwo.huff successfully added the numbers 1 and 2, returning 3! If you are new to working with assembly, I strongly suggest you do this as visualizing the individual instructions helps tremendously with learning.
In the next section we will walk through your contract’s execution given that you provide the calldata for 2 + 3. Encoded into uint256’s (32 bytes) the number 2 would become 0000000000000000000000000000000000000000000000000000000000000002 and the number 3 would become 0000000000000000000000000000000000000000000000000000000000000003.
This is illustrated in the table below:
| Type | Value | As calldata |
|---|---|---|
| uint256 | 2 | 0000000000000000000000000000000000000000000000000000000000000002 |
| uint256 | 3 | 0000000000000000000000000000000000000000000000000000000000000003 |
By putting the two together, we will send the following calldata to the contract.
0x00000000000000000000000000000000000000000000000000000000000000020000000000000000000000000000000000000000000000000000000000000003
Execution Walk Through
Line 1: 0x00 calldataload
This line reads the first 32 bytes of calldata onto the stack. The calldataload opcode takes a calldata offset from the stack as its input and returns 32bytes from that offset onto the stack.
Stack after operation: [2]
Line 2: 0x20 calldataload
Similarly, the second line reads the second 32 bytes of our calldata. By pushing the hex number 0x20 (32) onto the triggering calldataload.
Stack after operation: [3,2]
Line 3: add
The third line of ours calls the add opcode. This will take the top two items from the stack as inputs and return the sum of those two numbers. For the inputs [3,2] the result is [5]
Stack after operation [5]
Lines 4 and 5
The remainder of the contract is concerned with returning the result. EVM contracts can only return values that have been stored within the current executions memory frame. This is as the return opcode takes two values as inputs. The offset of memory to start returning from, and the length of memory to return.
In this case the return opcode will consume [0x00, 0x20]. Or 32 bytes in memory starting from byte 0.
This explains what 0x00 mstore is there for. mstore takes two items from the stack, [location_in_memory, value]. In our case we have [0x00, 0x5], this stores the value 5 into memory.
Interacting with this contract externally
As mentioned before, EVM contracts use an ABI to determine which function should be called. Currently, people interacting with addTwo’s execution is linear, allowing only one functionality. Most contracts will want to have more than one function. In order to accommodate for this we will have to do a little bit of restructuring.
The contract ABI specification dictates that contract calls will select which function they want to call by prepending a 4 byte (function selector) to their calls. The 4 bytes are sliced from the start of the keccak of the function’s abi definition. For example, addTwo(uint256,uint256)’s function selector will become 0x0f52d66e (You can confirm this by using a command line tool such as cast’s sig command, or online sites such as keccak256 online). If you are curious as to what these look like you can find a registry of common 4byte function selectors in the 4 byte directory.
Calculating the function selector each time can be tedious. To make life easy, huff has an included builtin __FUNC_SIG(). If a function interface is declared within the file’s current scope, it’s function selector will be calculated and inlined for you. You can view more information about huff’s builtin functions here.
Modifying our contract to accept external function calls
To accept external calls for multiple functions we will have to extract our addTwo logic into another macro. Then convert our MAIN macro into a function dispatcher.
#define function addTwo(uint256,uint256) view returns(uint256)
#define macro MAIN() = takes(0) returns(0) {
// Get the function selector
0x00
calldataload
0xE0
shr
// Jump to the implementation of the ADD_TWO function if the calldata matches the function selector
__FUNC_SIG(addTwo) eq addTwo jumpi
addTwo:
ADD_TWO()
}
#define macro ADD_TWO() = takes(0) returns(0) {
0x04 calldataload // load first 32 bytes onto the stack - number 1
0x24 calldataload // load second 32 bytes onto the stack - number 2
add // add number 1 and 2 and put the result onto the stack
0x00 mstore // place the result in memory
0x20 0x00 return // return the result
}
The first modifications we make will be within the ADD_TWO macro. On lines 1 and 2 we will shift the calldata offset by 4 bytes for both numbers, this is due to the 4 byte function selector that will be prepended to the calldata value.
Our MAIN macro has changed drastically.
The first 4 lines are concerned with isolating the function selector from the calldata.
0x00pushed[0]onto the stackcalldataloadtakes[0]as input and pushes the first 32 bytes of calldata onto the stack0xE0pushes[224]onto the stack. This magic number represents 256 bits - 32 bits (28 bytes).- When followed by the shr this will shift out calldata by 28 bytes and place the function selector onto the stack.
The following lines will match the function selector on the stack and then jump to the code location where that code is. Huff handles generating all jump logic for you.
Under the hood the ADD_TWO() macro bytecode will be inlined of ADD_TWO() in the main macro.
Now you should be able to use libraries like ethers, or other contracts to call your contract!
We hope this gives you a good understanding of the main concepts and all of the boiler plate you need to get started in Huff!
Next up, we’ll dive into more advanced Huff by creating a contract that returns a “Hello, world!” string!
Understanding the EVM
The Ethereum Virtual Machine, or EVM for short, is the brains behind Ethereum. It’s a computation engine, as the name suggests, similar to the virtual machines in Microsoft’s.NET Framework or interpreters for other bytecode-compiled programming languages like Java.
The EVM is the part of the Ethereum protocol that controls the deployment and execution of smart contracts. It can be compared to a global decentralized computer with millions of executable things (contracts), each with its own permanent data store.
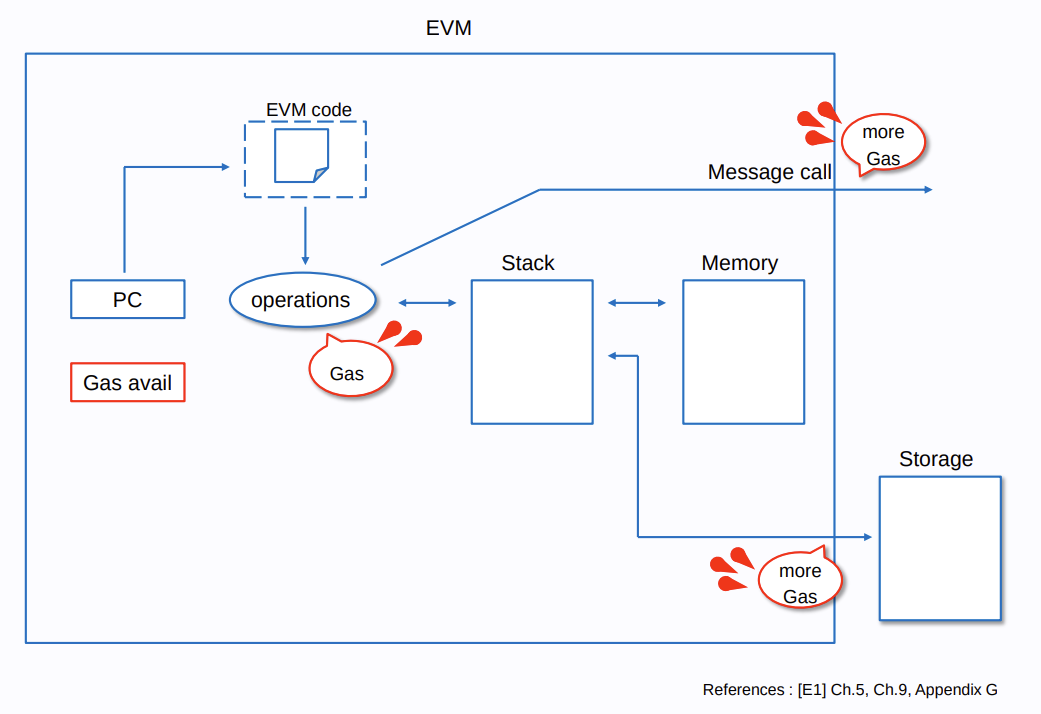
Technical
NOTE: This tutorial assumes that you are somewhat familiar with Solidity and therefore understand the basics of Ethereum development, including contracts, state, external calls, etc…
The Stack
The EVM runs as a stack machine with a depth of 1024 items. Each item is a 256 bit word (32 bytes), which was chosen due its compatibility with 256-bit encryption. Since the EVM is a stack-based VM, you typically PUSH data onto the top of it, POP data off, and apply instructions like ADD or MUL to the first few values that lay on top of it.
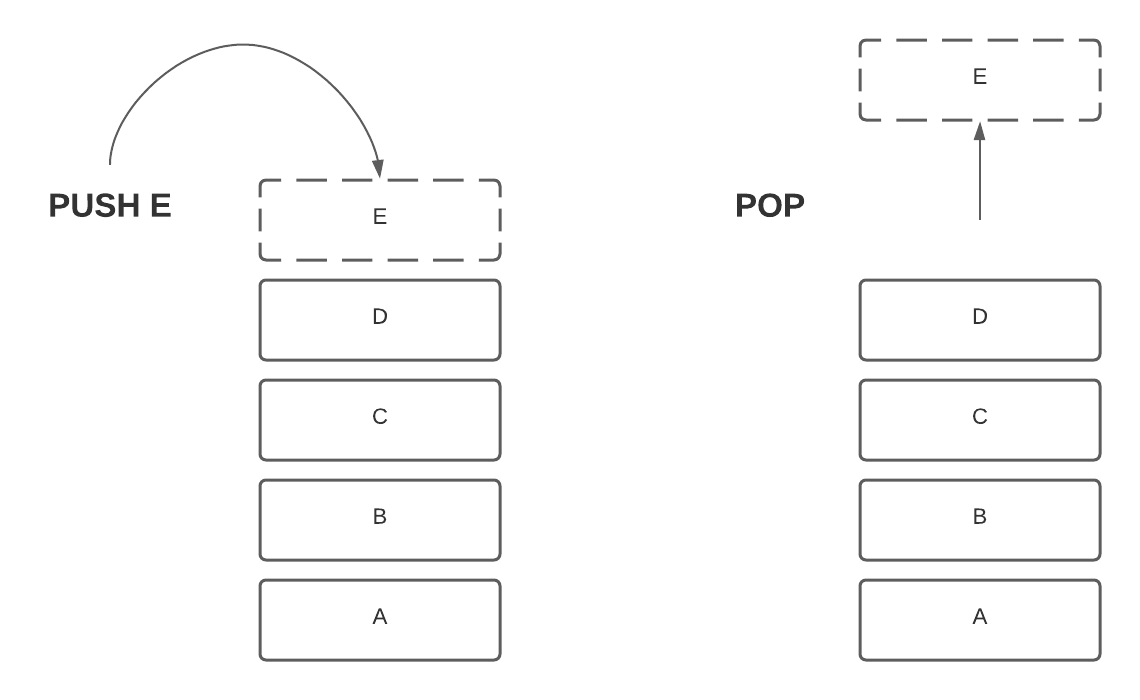
Here’s an example of what pushing to and popping from the stack looks like. On the left, we see an element, e, being pushed to the top of stack and on the right, we see how e is removed or “popped” from it.
It’s important to note that, while e was the last element to be pushed onto the stack (it is preceded by a, b, c, d), it is the first element to be removed when a pop occurs. This is because stacks follow the LIFO (Last In, First Out) principle, where the last element to be added is the first element to be removed.

Opcodes will often use stack elements as input, always taking the top (most recently added) elements. In the example above, we start with a stack consisting of a, b, c, and d. If you use the MUL opcode (which multiplies the two values at the top of the stack), c and d get popped from the stack and replaced by their product.
Memory and Calldata
In the EVM, memory can be thought of as an expandable, byte-addressed, 1 dimensional array. It starts out being empty, and it costs gas to read, write to, and expand it. Calldata on the other hand is very similar, but it is not able to be expanded or overwritten. It is included in the transaction’s payload, and acts as input for contract calls.
256 bit load & store:
- Reading from memory or calldata will always access the first 256 bits (32 bytes or 1 word) after the given pointer.
- Storing to memory will always write bytes to the first 256 bits (32 bytes or 1 word) after the given pointer.
Memory and calldata are not persistent, they are volatile- after the transaction finishes executing, they are forgotten.
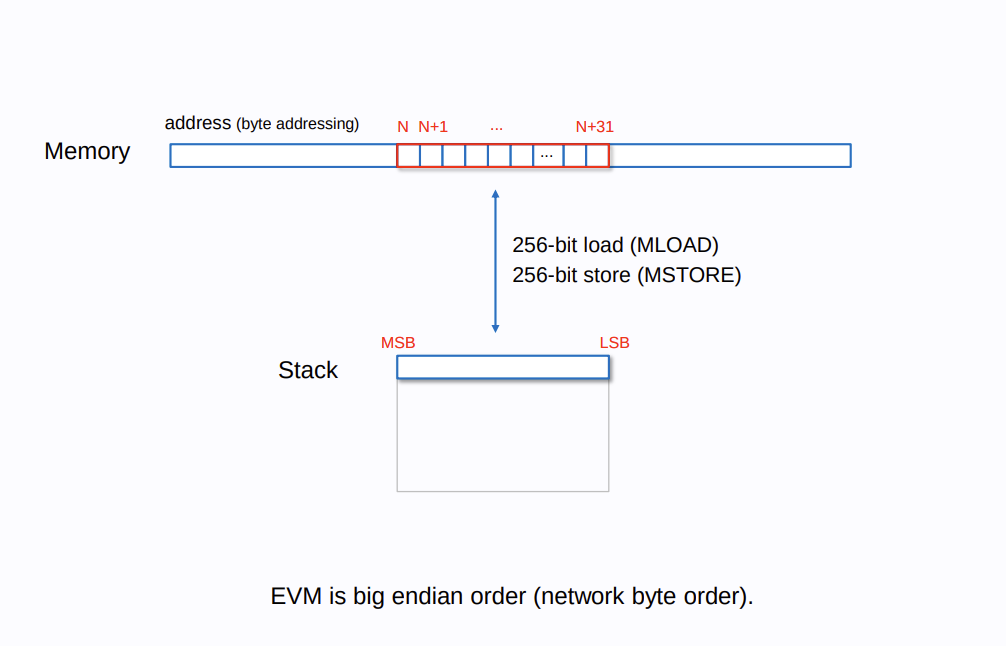
Mnenomic Example
PUSH2 0x1000 // [0x1000]
PUSH1 0x00 // [0x00, 0x1000]
MSTORE // []
// Memory: 0x0000000000000000000000000000000000000000000000000000000000001000
PUSH1 0x05 // [0x05]
PUSH1 0x20 // [0x20, 0x05]
MSTORE // []
// Memory: 0x00000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000000000005
PUSH1 0x00
MLOAD // [0x1000]
PUSH1 0x20
MLOAD // [0x05, 0x1000]
Storage
All contract accounts on Ethereum are able to store data persistently inside of a key-value store. Contract storage costs much more to read and write to than memory because after the transaction executes, all Ethereum nodes have to update the contract’s storage trie accordingly.
Instead of imagining a large 1 dimensional array like we did with memory, you can think of storage like a 256 bit ->
256 bit Map. There are a total of 2^256 storage slots due to the 32 byte key size.
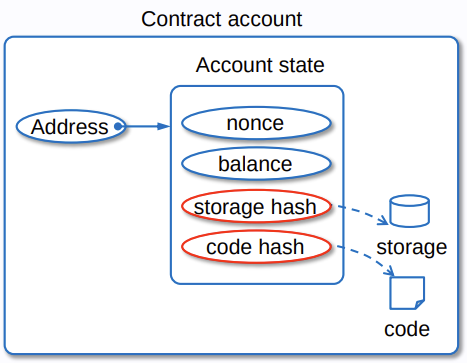
Mnenomic Example
PUSH20 0xdEaDbEeFdEaDbEeFdEaDbEeFdEaDbEeFdEaDbEeF // [dead_addr]
PUSH1 0x00 // [0x00, dead_addr]
SSTORE // []
PUSH20 0xC0FFEE0000000000000000000000000000000000 // [coffee_addr]
PUSH1 0x01 // [0x01, coffee_addr]
SSTORE // []
// Storage:
// 0x00 -> deadbeefdeadbeefdeadbeefdeadbeefdeadbeef
// 0x01 -> c0ffee0000000000000000000000000000000000
PUSH1 0x00
SLOAD // [dead_addr]
PUSH1 0x01
SLOAD // [coffee_addr, dead_addr]
For more information on the EVM, see the Resources section of the docs.
If any of this confuses you, don’t worry! While reading about the EVM will teach you the basics, actually writing assembly serves as the best way to get the hang of it (and it’s the most fun). Let’s dive into some simple projects.
Hello, world!
Note: This section is a continuation of ‘The Basics’. If you have not read it yet we recommend you take a look at it before continuing!
Within ‘The Basics’ we mentioned how "Hello, world!" is quite an advanced concept for Huff. The reason being that we need to have an understanding of how strings are encoded in the EVM.
Primer: ABI Encoding
As strings are dynamic types it is not as simple as returning the UTF-8 values for "Hello, world!" (0x48656c6c6f2c20776f726c6421). In the ABI standard, dynamic types are encoded in 3 parts, each which takes a full word (32 bytes) of memory.
- The offset of the dynamic data. (pointer to the start of the dynamic data, uint256)
- The length of the dynamic data. (uint256)
- The values of the dynamic data. (dynamic length)
Each part will look as follows for the string "Hello, world!":
Memory loc Data
0x00 0000000000000000000000000000000000000000000000000000000000000020 // The location of the "Hello, world!" data
0x20 000000000000000000000000000000000000000000000000000000000000000d // The length of "Hello, world!" in bytes
0x40 48656c6c6f2c20776f726c642100000000000000000000000000000000000000 // Value "Hello, world!"
Implementation
The following MAIN macro steps through this encoding in a clear way.
#define macro MAIN() = takes(0) returns(0) {
// store dynamic offset of 0x20 at 0x00
0x20 // [0x20]
0x00 // [0x00, 0x20]
mstore // []
// store string length of 0x0d at 0x20
0x0d // [0x0d]
0x20 // [0x20, 0x0d]
mstore // []
// store bytes for "Hello, world!" at 0x40
__RIGHTPAD(0x48656c6c6f2c20776f726c6421) // ["Hello, world!"]
0x40 // [0x40, "Hello, world!"]
mstore // []
// return full 96 byte value
0x60 // [0x60]
0x00 // [0x00, 0x60]
return // []
}
Have a look how memory is set and what is returned interactively with evm.codes playground for this example.
Advanced topic - The Seaport method of returning strings
Notice in the previous example that 3 adjacent words (32 bytes each) are being stored in memory. The 1st word is the offset and the 2nd word is the length. Both of these are left padded as all values are. The 3rd word is right padded because its bytes. Notice the length and the bytes are adjacent to each other in the memory schema. The length, “0d” is in memory location 0x3F and the first byte of “Hello, world!”, 0x48, is stored at 0x40.
If we take the length (0x0d) and the bytes (0x48656c6c6f2c20776f726c6421), and concatenate them, we would get: 0x0d48656c6c6f2c20776f726c6421 which becomes left padded value of:
0x000000000000000000000000000000000000000d48656c6c6f2c20776f726c6421
Now, instead of starting the second word at 0x20, if we offset that by 13 bytes (starting at 0x2d instead of 0x20) then it lines up so that the 0d falls in the right most (lowest) bits of the second word (location 0x3F) and the remaining bytes start immediately in the first leftmost (highest) byte of the third word (location 0x40).
This is a common technique in Huff and was also made popular by Seaport’s _name() function.
Here is a diagram illustrating the “Seaport” method using the string “TKN”:

Testing Huff with Foundry
While Huff can be compiled through the command line tool, you can also use Foundry to test your code. Foundry is a blazing fast, portable, modular toolkit for Ethereum application development. Foundry enables you to easily compile your contracts and write robust unit tests to ensure that your code is safe. This is especially important for Huff contracts, where there aren’t many automatic safety-checks on your code.
You can use the two together via the foundry-huff-neo library.
Utilizing Foundry-Huff
If you have an existing Foundry project, you can simply install the necessary dependencies by running:
forge install cakevm/foundry-huff-neo
You also must add the following line to your foundry.toml file to ensure that the foundry-huff library has access to your environment in order to compile the contract:
ffi = true
You can then use HuffNeoDeployer contract to compile and deploy your Huff contracts for you using the deploy function. Here’s a quick example:
import { HuffNeoDeployer } from "foundry-huff-neo/HuffDeployer.sol";
contract HuffDeploymentExample {
function deploy() external returns(address) {
return new HuffNeoDeployer().deploy("MyContract");
}
}
For more information on how to use Foundry, check out the Foundry GitHub Repository and Foundry Book.
Using the Project Template
If you’re looking to create a new project from scratch, you can use the project template.
We go over using the project template in Project Quickstart.
Simple Storage
So far the two examples we have looked at have explored slicing bytes from calldata, storing in memory and returning values. Now we’re going to address the missing piece of the puzzle that all EVM devs fear, storage.
Storage in Huff
Thankfully working with storage isn’t too complicated, Huff abstracts keeping track of storage variables through the FREE_STORAGE_POINTER() keyword. An example of which will be shown below:
#define constant STORAGE_SLOT0 = FREE_STORAGE_POINTER()
#define constant STORAGE_SLOT1 = FREE_STORAGE_POINTER()
#define constant STORAGE_SLOT2 = FREE_STORAGE_POINTER()
Storage slots are simply keys in a very large array where contracts keep their state. The compiler will assign STORAGE_SLOT0 the value 0, STORAGE_SLOT1 the value 1 etc. at compile time. Throughout your code you just reference the storage slots the same way constants are used in any language.
Setting storage
First define the constant that will represent your storage slot using the FREE_STORAGE_POINTER() keyword.
#define constant VALUE = FREE_STORAGE_POINTER()
We can then reference this slot throughout the code by wrapping it in square brackets - like so [VALUE]. The example below demonstrates a macro that will store the value 5 in the slot [VALUE].
#define macro SET_5() = takes(0) returns(0) {
0x5 // [0x5]
[VALUE] // [value_slot_pointer, 0x5]
sstore // []
}
Test this out interactively here ([VALUE] has been hardcoded to 0)
Reading from storage
Now you know how to write to storage, reading from storage is trivial. Simply replace sstore with sload and your ready to go. We are going to extend our example above to both write and read from storage.
#define macro SET_5_READ_5() = takes(0) returns(0) {
0x5
[VALUE]
sstore
[VALUE]
sload
}
Nice! Once again you can test this out over at evm.codes. Notice how 5 reappears on the stack after executing the sload instruction.
Simple Storage Implementation
Now we can read and write to storage, lets attempt the famous SimpleStorage starter contract from remix.
First off, lets create our interface:
#define function setValue(uint256) nonpayable returns ()
#define function getValue() nonpayable returns (uint256)
Now lets define our storage slots:
#define constant VALUE = FREE_STORAGE_POINTER()
Onto the fun part, the logic. Remember from the addTwo example we can read calldata in 32 byte chunks using the calldataload opcode, lets use that knowledge to get read our uint256.
#define macro SET_VALUE() = takes(0) returns(0) {
// Read uint256 from calldata, remember to read from byte 4 to allow for the function selector!
0x04 // [0x04]
calldataload // [value]
// Get pointer and store
[VALUE] // [value_ptr, value]
sstore // []
}
After completing the previous examples we hope that writing Huff is all starting to click! This pattern will be extremely common when writing your own contracts, reading from calldata then storing values in memory or storage.
Next up is reading the stored value.
#define macro GET_VALUE() = takes(0) returns(0) {
// Read uint256 from storage
[VALUE] // [value_ptr]
sload // [value]
// Store the return value in memory
0x00 // [0x00, value]
mstore // []
// Return the first 32 bytes of memory containing our uint256
0x20 // [0x20]
0x00 // [0x00, 0x20]
return // []
}
First off, we read the storage value using a similar technique to our prior example. Prepare the return value by storing it in memory. Then return the value from memory. It’s all coming together!
To call our new macros from external functions we have to create a dispatcher!
#define macro MAIN() = takes(0) returns(0) {
// Get the function selector
0x00 calldataload 0xe0 shr
dup1 __FUNC_SIG(setValue) eq setValue jumpi // Compare function selector to setValue(uint256)
dup1 __FUNC_SIG(getValue) eq getValue jumpi // Compare the function selector to getValue()
// dispatch
setValue:
SET_VALUE()
getValue:
GET_VALUE()
0x00 0x00 revert
}
Now all of it together!
// Interface
#define function setValue(uint256) nonpayable returns ()
#define function getValue() nonpayable returns (uint256)
// Storage
#define constant VALUE = FREE_STORAGE_POINTER()
// External function macros
// setValue(uint256)
#define macro SET_VALUE() = takes(0) returns(0) {
// Read uint256 from calldata, remember to read from byte 4 to allow for the function selector!
0x04 // [0x04]
calldataload // [value]
// Get pointer and store
[VALUE] // [value_ptr, value]
sstore // []
}
// getValue()
#define macro GET_VALUE() = takes(0) returns(0) {
// Read uint256 from storage
[VALUE] // [value_ptr]
sload // [value]
// Store the return value in memory
0x00 // [0x00, value]
mstore // []
// Return the first 32 bytes of memory containing our uint256
0x20 // [0x20]
0x00 // [0x00, 0x20]
return // []
}
// Main
#define macro MAIN() = takes(0) returns(0) {
// Get the function selector
0x00 calldataload 0xe0 shr
dup1 __FUNC_SIG(setValue) eq setValue jumpi // Compare function selector to setValue(uint256)
dup1 __FUNC_SIG(getValue) eq getValue jumpi // Compare the function selector to getValue()
// dispatch
setValue:
SET_VALUE()
getValue:
GET_VALUE()
0x00 0x00 revert
}
Congratulations! You’ve made it through the crust of writing contracts in Huff. For your next steps we recommend taking what you have learned so far in addTwo, “Hello, World!” and SimpleStorage into a testing framework like Foundry. Happy hacking!
Function Dispatching
Function dispatching is something that is fundamental to any Huff contract. Unlike Solidity and Vyper; Huff does not abstract function dispatching. In this section we will go over how dispatching is performed in the other languages, and how you may go about it in Huff.
What is the problem?
In the evm, contracts are interacted with by sending messages to them. The ABI standard exists as a canonical way to encode these messages, handling how inputs to functions should be encoded. These strict rules are what allow contracts to understand each other. The ABI standard also tells the contract which function the message intends to interact with. This is done by encoding a 4 byte selector at the beginning of the message. This 4 byte selector is the first 4 bytes of the keccak of the function’s signature string. For example, the keccak256 hash of the string “myFunction(address,uint256)” is 0x451c00ddd225deee9948ba5eca26042a5ea1cc0980e5a5fb0a057f90567af5e0. So the first 4 bytes 0x451c00dd is what Solidity uses as the function signature. If you have written interfaces in solidity you may not realize that you are just providing your current contract the ability to generate the 4 byte selectors of a foreign contract.
The rest of this section will detail two types of dispatching, linear dispatching and binary search dispatching.
Linear Dispatching
From reading the above, or from reading a Huff contract before you may have developed some intuition about how the simplest way to perform dispatching is - A linear lookup. This method will extract the function selector from the calldata message, then brute force compare it to every other function in the contract.
The example below shows what a linear dispatcher may look like for a standard ERC20 token:
// Interface
#define function allowance(address,address) view returns (uint256)
#define function approve(address,uint256) nonpayable returns ()
#define function balanceOf(address) view returns (uint256)
#define function DOMAIN_SEPARATOR() view returns (bytes32)
#define function nonces(address) view returns (uint256)
#define function permit(address,address,uint256,uint256,uint8,bytes32,bytes32) nonpayable returns ()
#define function totalSupply() view returns (uint256)
#define function transfer(address,uint256) nonpayable returns ()
#define function transferFrom(address,address,uint256) nonpayable returns ()
#define function decimals() nonpayable returns (uint256)
#define function name() nonpayable returns (string)
#define function symbol() nonpayable returns (string)
// Function Dispatching
#define macro MAIN() = takes (1) returns (1) {
// Identify which function is being called.
0x00 calldataload 0xE0 shr // [func_sig]
dup1 __FUNC_SIG(permit) eq permitJump jumpi
dup1 __FUNC_SIG(nonces) eq noncesJump jumpi
dup1 __FUNC_SIG(name) eq nameJump jumpi
dup1 __FUNC_SIG(symbol) eq symbolJump jumpi
dup1 __FUNC_SIG(decimals) eq decimalsJump jumpi
dup1 __FUNC_SIG(DOMAIN_SEPARATOR) eq domainSeparatorJump jumpi
dup1 __FUNC_SIG(totalSupply) eq totalSupplyJump jumpi
dup1 __FUNC_SIG(balanceOf) eq balanceOfJump jumpi
dup1 __FUNC_SIG(allowance) eq allowanceJump jumpi
dup1 __FUNC_SIG(transfer) eq transferJump jumpi
dup1 __FUNC_SIG(transferFrom) eq transferFromJump jumpi
dup1 __FUNC_SIG(approve) eq approveJump jumpi
// Revert if no match is found.
0x00 dup1 revert
allowanceJump:
ALLOWANCE()
approveJump:
APPROVE()
balanceOfJump:
BALANCE_OF()
decimalsJump:
DECIMALS()
domainSeparatorJump:
DOMAIN_SEPARATOR()
nameJump:
NAME()
noncesJump:
NONCES()
permitJump:
PERMIT()
symbolJump:
SYMBOL()
totalSupplyJump:
TOTAL_SUPPLY()
transferFromJump:
TRANSFER_FROM()
transferJump:
TRANSFER()
}
There is one extremely important piece of code you will use in almost all of your Huff contracts:
0x00 calldataload 0xE0 shr
This loads the four byte function selector onto the stack. 0x00 calldataload will load 32 bytes starting from position 0 onto the stack (if the calldata is less than 32 bytes then it will be right padded with zeros). 0xE0 shr right shifts the calldata by 224 bits, leaving 32 bits or 4 bytes remaining on the stack.
Despite this seeming like a rather naive approach, for most contracts it is often the most effective. As this is one large if else if chain, you can optimize by placing “hot functions” towards the top of your chain. Functions towards the front will cost less gas to invoke, but be aware as your function approaches the end of the chain it can really get expensive!
This method seems naive, however this is exactly how Vyper and Solidity* implement linear dispatching. If you want it to be cheaper to call, just move it higher up in the contract!
* Solidity implements this method when there are fewer than 5 functions, or the number of optimizer runs is small. Otherwise, it will use binary search dispatching.
You may be wondering what the series of jump labels followed by implementation macros mean. A good mental model is that the entire of your contract exists within your MAIN macro. If a macro is not referred to within main or nested within a macro that is invoked within MAIN then it will not be included in your contract. In reality the above contract when compiled looks like this:
0x[dispatcher]<allowanceJumpLabel>[ALLOWANCE MACRO]<approveJumpLabel>[APPROVE MACRO]<balanceOfJump>[BALANCE_OF MACRO] ... <transferFromLabel>[TRANSFER_FROM MACRO]<transferJump>[TRANSFER MACRO]
In Huff all of your macros are inlined into one long bytecode string (this is also true for Vyper and Solidity!). Due to this property it is salient that you terminate ALL of your top-level macros with some form of escape opcode (return, stop, revert). If you don’t do this your macro WILL continue to execute which ever macro is inlined next until a return condition is found.
For example:
#define function returnOne() public returns(uint256)
#define function returnTwo() public returns(uint256)
/// @notice returns the value one
#define macro RETURN_ONE() = {
0x01 0x00 mstore
0x20 0x00 return
}
/// @notice places the value 2 onto the stack
#define macro RETURN_TWO() = {
0x02
}
#define macro MAIN() = {
0x00 calldataload 0xE0 shr
// Dispatcher
dup1 __FUNC_SIG(returnOne) eq returnOneJump jumpi
dup1 __FUNC_SIG(returnTwo) eq returnTwoJump jumpi
// Macros
returnTwo:
RETURN_TWO()
returnOne:
RETURN_ONE()
}
In the above macro, regardless if what message is sent to it, it will ALWAYS return the value 1. As the macro RETURN_TWO does not terminate, it will roll over into the execution of RETURN_ONE, terminating with returning the value one. As there is no guard to protect against non valid function signatures any message, even if it matches nothing in the dispatcher will return the value 1.
One way we can handle no valid function selector being found is by inserting 0x00 0x00 revert in-between our dispatcher and our macro jump labels as so:
#define macro MAIN() = {
0x00 calldataload 0xE0 shr
dup1 __FUNC_SIG(returnOne) eq returnOneJump jumpi
dup1 __FUNC_SIG(returnTwo) eq returnTwoJump jumpi
0x00 0x00 revert
returnTwo:
RETURN_TWO()
returnOne:
RETURN_ONE()
}
Please keep this behavior in mind when writing Huff contracts, especially when dealing with administration functions, running into a SET_OWNER() macro could allow anyone to take control of your contract. There is a more advanced way of jumping over the macro calling logic that is used with Huff “inheritance” pattern that we will discuss in another section.
Binary Search Dispatching
Another method of function dispatching is by doing a binary search to find the correct selector. This is great for contracts with lots and lots of functions as it makes the dispatching cost more predictable / steady (No more checking every single branch of the if else chain). In this method, we order our function selectors by their keccak, then pivot about a number of jump points until we reach the desired function. The number of jump points you include is up to you. The more jumps you add the more consistent your jump price will be, however, be mindful of the gas cost for comparisons. Generally, each split will add 16-18 bytes of additional code (remember there is a jump out of each pivot point).
To implement this approach you will need to manually calculate the function selectors and order them by hand. But do not worry, this can be done easily with a script.
Here is an example implementation of a binary search dispatch.
// Define Interface
#define function allowance(address,address) view returns (uint256)
#define function approve(address,uint256) nonpayable returns ()
#define function balanceOf(address) view returns (uint256)
#define function DOMAIN_SEPARATOR() view returns (bytes32)
#define function nonces(address) view returns (uint256)
#define function permit(address,address,uint256,uint256,uint8,bytes32,bytes32) nonpayable returns ()
#define function totalSupply() view returns (uint256)
#define function transfer(address,uint256) nonpayable returns ()
#define function transferFrom(address,address,uint256) nonpayable returns ()
#define function decimals() nonpayable returns (uint256)
#define function name() nonpayable returns (string)
#define function symbol() nonpayable returns (string)
// Function Dispatching
#define macro MAIN() = takes (1) returns (1) {
// Identify which function is being called.
// [func sig]
0x00 calldataload 0xE0 shr
// The function selector of the pivot (number of selectors / 2)
dup1 __FUNC_SIG(balanceOf) lt pivot0 jumpi
// pivot 2
dup1 __FUNC_SIG(totalSupply) lt pivot00 jumpi
// 1
dup1 __FUNC_SIG(name) eq nameJump jumpi
// 2
dup1 __FUNC_SIG(approve) eq approveJump jumpi
// 3
dup1 __FUNC_SIG(totalSupply) eq totalSupplyJump jumpi
not_found jump
pivot00:
// 4
dup1 __FUNC_SIG(transferFrom) eq transferFromJump jumpi
// 5
dup1 __FUNC_SIG(decimals) eq decimalsJump jumpi
// 6
dup1 __FUNC_SIG(DOMAIN_SEPARATOR) eq domainSeparatorJump jumpi
not_found jump
pivot0:
dup1 __FUNC_SIG(symbol) lt pivot11 jumpi
// 7
dup1 __FUNC_SIG(balanceOf) eq balanceOfJump jumpi
// 8
dup1 __FUNC_SIG(nonces) eq noncesJump jumpi
// 9
dup1 __FUNC_SIG(symbol) eq symbolJump jumpi
not_found jump
pivot11:
// 10
dup1 __FUNC_SIG(transfer) eq transferJump jumpi
// 11
dup1 __FUNC_SIG(permit) eq permitJump jumpi
// 12
dup1 __FUNC_SIG(allowance) eq allowanceJump jumpi
not_found:
// Revert if no match is found.
0x00 dup1 revert
allowanceJump:
ALLOWANCE()
approveJump:
APPROVE()
balanceOfJump:
BALANCE_OF()
decimalsJump:
DECIMALS()
domainSeparatorJump:
DOMAIN_SEPARATOR()
nameJump:
NAME()
noncesJump:
NONCES()
permitJump:
PERMIT()
symbolJump:
SYMBOL()
totalSupplyJump:
TOTAL_SUPPLY()
transferFromJump:
TRANSFER_FROM()
transferJump:
TRANSFER()
}
Fallback functions
In solidity there are two special functions, fallback and receive. Both are relatively straightforward to implement in Huff.
To implement fallback, just place a macro at the end of your dispatch logic, take for example the following fallback function that will always return the value 1:
#define macro FALLBACK() = {
0x01 0x00 mstore
0x20 0x00 return
}
Implementing it as a fallback is as simple as throwing it after you have exhausted your switch cases.
#define macro MAIN() = takes (1) returns (1) {
// Identify which function is being called.
// [func sig]
0x00 calldataload 0xE0 shr
dup1 __FUNC_SIG(permit) eq permitJump jumpi
...
dup1 __FUNC_SIG(approve) eq approveJump jumpi
FALLBACK()
permitJump:
PERMIT()
...
approveJump:
APPROVE()
}
If you want to implement both fallback and receive macros you can do the following:
#define macro MAIN() = takes (1) returns (1) {
// Identify which function is being called.
// [func sig]
0x00 calldataload 0xE0 shr
dup1 __FUNC_SIG(permit) eq permitJump jumpi
...
dup1 __FUNC_SIG(approve) eq approveJump jumpi
# Jump into the receive function if msg.value is not zero
callvalue receive jumpi
FALLBACK()
receive:
RECEIVE()
permitJump:
PERMIT()
...
approveJump:
APPROVE()
}
Huff Neo CLI
While most of the time you will be compiling your Huff contracts in a foundry project using the foundry-huff-neo library, the compiler’s CLI offers some additional configuration options as well as some useful utilities.
Options
Huff Language Compiler built in Pure Rust.
Usage: hnc [OPTIONS] [PATH] [COMMAND]
Commands:
test Test subcommand
help Print this message or the help of the given subcommand(s)
Arguments:
[PATH] The contract(s) to compile
Options:
-s, --source-path <SOURCE> The contracts source path [default: ./contracts]
-o, --output <OUTPUT> The output file path
-d, --output-directory <OUTPUTDIR> The output directory [default: ./artifacts]
-i, --inputs <INPUTS>... The input constructor arguments
-n, --interactive Interactively input the constructor args
-a, --artifacts Whether to generate artifacts or not
--relax-jumps Apply branch relaxation to minimize deployment gas
-g, --interface [<INTERFACE>...] Generate solidity interface for a Huff artifact
-b, --bytecode Generate and log bytecode
-r, --bin-runtime Generate and log runtime bytecode
-p, --print Prints out to the terminal
-v, --verbose Verbose output
-l, --label-indices Prints out the jump label PC indices for the specified contract
-c, --constants <CONSTANTS>... Override / set constants for the compilation environment
-m, --alt-main <ALTERNATIVE_MAIN> Compile a specific macro
-t, --alt-constructor <ALT_CONSTRUCTOR> Compile a specific constructor macro
-e, --evm-version <EVM_VERSION> Set the EVM version [default: osaka]
--flattened-source Output the flattened source code with all dependencies resolved
--no-size-limit Skip the contract size limit check (EIP-170: 24576 bytes)
-V, --version Print version
-h, --help Print help
-a Artifacts
Passing the -a flag will generate Artifact JSON file(s) in the ./artifacts
directory or wherever the -d flag designates. The Artifact JSON contains
the following information:
- File
- Path
- Source
- Dependencies
- Bytecode
- Runtime Bytecode
- Contract ABI
Example:
hnc ./src/ERC20.huff -a
-b Bytecode
Passing the -b flag will tell the compiler to log the bytecode generated during
the compilation process to the console.
Example:
hnc ./src/ERC20.huff -b
-c Constants
Arguments: [CONSTANTS]
Passing the -c flag allows you to override and set constants for the current compilation environment. Values can be:
- Hex literals in
0xformat (up to 32 bytes) true(equivalent to0x01)false(equivalent to0x00)
Example:
hnc ./Test.huff -c MY_CONST=0x01 MY_OTHER_CONST=0xa57b DEBUG=true
-d Output directory
Arguments: <OUTPUT_DIR>, Default: ./artifacts
Passing the -d flag allows you to designate the directory that the Artifact
JSON file will be exported to.
Example:
hnc ./src/ERC20.huff -d ./my_artifacts
-e EVM Version
Arguments: <EVM_VERSION>, Default: osaka
Passing the -e flag allows you to set the target EVM version for compilation.
This determines which opcodes are available. Supported versions:
paris- PREVRANDAOshanghai- PUSH0cancun- TLOAD, TSTORE, MCOPY, BLOBHASH, BLOBBASEFEEprague- No new opcodesosaka- CLZ (default)
Example:
hnc ./src/ERC20.huff -e cancun
--flattened-source
Passing the --flattened-source flag outputs the flattened source code with all
dependencies and includes resolved into a single output.
Example:
hnc ./src/ERC20.huff --flattened-source
--no-size-limit
Passing the --no-size-limit flag bypasses the EIP-170 contract size limit check.
By default, compilation fails if the runtime bytecode exceeds 24,576 bytes (the
maximum deployable contract size on Ethereum mainnet).
Example:
hnc ./src/LargeContract.huff -b --no-size-limit
-g Interface
Passing the -g flag will generate a Solidity interface for the Huff contract
provided. This interface is generated based off of the function and event
definitions within the contract.
The solidity file will always be named I<HUFF_FILE_NAME>.sol, and it will be
saved in the same directory as the Huff contract itself.
Example:
hnc ./src/ERC20.huff -g
-i Inputs
Arguments: [CONSTRUCTOR_ARGS]
Passing the -i flag allows you to set the constructor arguments for the
contract that is being compiled. All inputs should be separated by a comma.
If you’d like to input the constructor arguments interactively instead,
use the -n flag.
Example (assuming ERC20.huff’s constructor accepts a String and a uint):
hnc ./src/ERC20.huff -i "TestToken", 18
-l Label Indices
Passing the -l flag prints out the jump label PC (program counter) indices
for the specified contract. This is useful for debugging and understanding
where labels resolve to in the final bytecode.
Example:
hnc ./src/ERC20.huff -l
-m Alternative Main
Arguments: <ALTERNATIVE_MAIN>
Passing the -m flag allows you to compile a specific macro as the main
entry point instead of the default MAIN macro.
Example:
hnc ./src/Contract.huff -m MY_CUSTOM_MAIN
-n Interactive Inputs
Passing the -n flag allows you to input constructor arguments
interactively through the CLI rather than via the -i flag.
Example:
hnc ./src/ERC20.huff -n
-o Output
Arguments: <FILE_PATH>
Passing the -o flag allows you to export the artifact to a specific file
rather than a folder.
Example:
hnc ./src/ERC20.huff -o ./artifact.json
-p Print
Passing the -p flag prints the compilation output to the terminal.
Example:
hnc ./src/ERC20.huff -p
--relax-jumps
Passing the --relax-jumps flag applies branch relaxation to minimize deployment
gas costs. When enabled, all pushes for jumps will be minimized to PUSH1 where
possible. This can reduce deployment gas costs but has no effect on runtime gas
costs. Only applies to label references used in JUMPI and JUMP opcodes.
Example:
hnc ./src/ERC20.huff --relax-jumps -b
-s Source Path
Arguments: <CONTRACTS_FOLDER>, Default: ./contracts
Passing the -s flag allows you to change the directory that the compiler scans
for Huff contracts.
Example:
hnc -s ./src/
-t Alternative Constructor
Arguments: <ALTERNATIVE_CONSTRUCTOR>
Passing the -t flag allows you to compile a specific macro as the constructor
entry point instead of the default CONSTRUCTOR macro.
Example:
hnc ./src/Contract.huff -t MY_CUSTOM_CONSTRUCTOR
-r Runtime Bytecode
Passing the -r flag will tell the compiler to print the runtime bytecode
of the compiled contract.
-v Verbose Output
Passing the -v flag will tell the compiler to print verbose output during
the compilation process. This output can be useful for debugging contract
as well as compiler errors.
Example:
hnc ./src/ERC20.huff -v
Subcommands
test
- Format:
hnc ./path/to/Contract.huff test [-f <list|table|json>] [-m <TEST_NAME>]
The test subcommand is the entry point to running tests within a Huff contract.
Optional Flags
-for--format: Formats the test report as a list, table, or JSON.-mor--match: Runs a specific test with the name passed to this flag.
Style Guide
The following is a style-guide for the Huff-Std library. Feedback and discussion is welcome.
Formatting
Lines should be no greater than 100 characters (disregarding long constant names/values).
Files should use 4 spaces for indentions.
File Structure
The file structure of a Huff contract so follow this:
/* Imports */
#include "./contracts/utils/ExampleImport1.huff"
#include "./contracts/utils/ExampleImport2.huff"
/* Function Interfaces */
#define function exampleFunction1(address,uint256) nonpayable returns ()
#define function exampleFunction2(address,uint256) nonpayable returns ()
#define function exampleFunction3(address,address,uint256) nonpayable returns ()
#define function exampleFunction4(address,uint256) nonpayable returns ()
#define event ExampleEvent1(address indexed example)
#define event ExampleEvent2(address indexed example)
/* Events Signatures */
#define constant EXAMPLE_EVENT_SIGNATURE1 = 0xDDF252AD1BE2C89B69C2B068FC378DAA952BA7F163C4A11628F55A4DF523B3EF
#define constant EXAMPLE_EVENT_SIGNATURE2 = 0x8C5BE1E5EBEC7D5BD14F71427D1E84F3DD0314C0F7B2291E5B200AC8C7C3B925
/* Storage Slots */
#define constant EXAMPLE_SLOT1 = FREE_STORAGE_POINTER()
#define constant EXAMPLE_SLOT2 = FREE_STORAGE_POINTER()
#define constant EXAMPLE_SLOT3 = FREE_STORAGE_POINTER()
/* Constructor */
#define macro CONSTRUCTOR() = takes(0) returns (0) {}
/* Macros */
#define macro MYMAC() = takes (0) returns (0) {}
/* Entry Point */
#define macro MAIN() = takes (0) returns (0) {}
The next aspect of this is more complicated, because it depends on the context and functionality of the contract. Essentially, we want to categorize macros into sections based on their functionality. Here is an example from an existing ERC20 contract:
/* Accounting Macros */
#define macro BALANCE_OF() = takes (0) returns (0) {}
#define macro TOTAL_SUPPLY() = takes (0) returns (0) {}
#define macro ALLOWANCE() = takes (0) returns (0) {}
/* Transfer Macros */
#define macro TRANSFER_TAKE_FROM(error) = takes(3) returns (3) {}
#define macro TRANSFER_GIVE_TO() = takes(3) returns (0) {}
#define macro TRANSFER() = takes(0) returns(1) {}
/* Approval Macros */
#define macro APPROVE() = takes (0) returns (0) {}
/* Mint Macros */
#define macro MINT() = takes(0) returns (0) {}
Natspec Comments
To make Huff as easy as possible to transition to from Solidity, Natspec comments are encouraged for use in the contract.
At the top of a Huff file, it is recommended to include the following natspec comments:
/// @title The title of the contract
/// @author The contract author
/// @notice A short description of the contract
Macros are also encouraged to include natspec comments where useful. For example, huffmate’s Multicallable Huff Contract contains the following macro natspec above the MULTICALL() macro.
/// @notice Multicall function entry point.
/// @dev This macro should be placed alone under a function selector's jump label.
///
/// Expected calldata: `bytes[]` containing valid ABI-encoded function calls
/// as elements.
///
/// Note: this macro only allows for multicalling functions that are within
/// the contract it is invoked in.
Code Comments
Comments should use the double slash (//) syntax, unless they are used to mark a new section of the codebase (see above).
Comments describing the functionality of a statement, macro, etc should be on the line(s) prior.
// owner slot
#define constant OWNER_SLOT = FREE_STORAGE_POINTER()
Comments indicating the stack after an instruction should be on the right of the instruction. Instruction comments within the same code block should be aligned vertically with the right-most instruction comment. The right-most instruction comment should be one “tab” from the right of the instruction.
0x20 // [value]
0x00 // [offset, value]
mstore // []
Macro Definition
Macros with a non-zero takes expectation should include a single comment at the start of the code block indicating the expected stack in the following format.
// Reverts if caller is not the owner.
#define macro ONLY_OWNER() = takes (1) returns (0) {
// takes: [calling_address]
[OWNER_SLOT] // [owner_slot, calling_address]
sload // [owner_address, calling_address]
eq // [is_owner]
is_owner // [is_owner_jumpdest, is_owner]
jumpi // []
0x00 // [revert_size]
0x00 // [revert_offset, revert_size]
revert // []
is_owner: // []
}
The exception to this would be the function selector switch in the contract’s entry point, given its common usage.
The contract entry point should contain the function selector switch first, with each jump destination having one additional line of whitespace between one another.
// Entry point.
#define function add(uint256, uint256) view returns (uint256)
#define function sub(uint256, uint256) view returns (uint256)
#define macro MAIN() = takes (0) returns (0) {
// Grab the function selector from the calldata
0x00 calldataload 0xE0 shr // [selector]
dup1 __FUNC_SIG(add) eq add_func jumpi // [selector]
dup1 __FUNC_SIG(sub) eq sub_func jumpi // [selector]
// Revert if no functions match
0x00 0x00 revert
add_func:
ADD()
sub_func:
SUB()
}
Function ABI Definition
This is entirely optional, feedback is appreciated here.
Defining an external function ABI should consist of two components, the function definition and the 4 byte function selector defined as a constant. Defining a constant representing the function selector directly following a function definition makes for clear usage in the contract’s entry point.
The function selector definition should be screaming snake case suffixed with _SEL. This also makes clear the function selector switch’s behavior.
Omitting whitespace between the function definition and selector would also make the relationship between the two more clear.
#define function add(uint256, uint256) view returns (uint256)
#define macro ADD() = takes (0) returns (0) {}
#define macro MAIN() = takes (0) returns (0) {
// Grab the function selector from the calldata
0x00 calldataload 0xE0 shr // [selector]
dup1 __FUNC_SIG(add) eq add_func jumpi // [selector]
// Revert if no functions match
0x00 0x00 revert
add_func:
ADD()
}
Event ABI Definition
This is entirely optional, feedback is appreciated here.
Defining an event ABI should consist of two components, the event definition and the 32 byte event signature defined as a constant.
The event signature should be screaming snake case suffixed with _SIG.
Omitting whitespace between the event definition and signature would also make the relationship between the two more clear.
#define event NewOwner(address)
#define constant NEW_OWNER_SIG = 0x3edd90e7770f06fafde38004653b33870066c33bfc923ff6102acd601f85dfbc
Jump Labels
Open to suggestions here.
Should instructions following jump labels be indented? Doing so may make execution unclear, as the indention is not taken into consideration at compile time. In the following example, the operation0 jump label’s subsequent code is executed, but execution continues at the operation1 label, despite it not being clear this is the case.
operation0
jump
// ....
operation0:
0x01 // [b]
0x02 // [a, b]
add // [sum]
operation1:
0x02 // [b, sum]
0x01 // [a, b, sum]
sub // [diff, sum]
It may be best to omit indentation, at least in the standard library.
operation0
jump
// ....
operation0:
0x01 // [b]
0x02 // [a, b]
add // [sum]
operation1:
0x02 // [b, sum]
0x01 // [a, b, sum]
sub // [diff, sum]
Contract Call Return
Open to suggestions here.
There is an issue with using something such as a reentrancy guard, which is a potential return instruction before the lock is restored to the unlocked state. Take the following example.
#define function doAction() view returns (uint256)
#define constant LOCK_SLOT = FREE_STORAGE_POINTER()
#define macro NON_REENTRANT() = takes (0) returns (0) {
[LOCK_SLOT] // [lock_slot]
sload // [lock]
iszero // [is_unlocked]
unlocked // [unlocked_jumpdest]
jumpi // []
0x00 // [size]
0x00 // [offset, size]
revert // []
unlocked: // []
0x01 // [lock_value]
[LOCK_SLOT] // [lock_slot, lock_value]
sstore // []
}
#define macro UNLOCK() = takes (0) returns (0) {
0x01 // [lock_value]
[LOCK_SLOT] // [lock_slot, lock_value]
sstore // []
}
#define macro DO_ACTION() = takes (0) returns (0) {
0x45 // [value]
0x00 // [offset, value]
mstore // []
0x20 // [size]
0x00 // [offset, size]
return
}
#define macro MAIN() = takes (0) returns (0) {
// Grab the function selector from the calldata
0x00 calldataload 0xE0 shr // [selector]
dup1 __FUNC_SIG(doAction) eq do_action jumpi // [selector]
// Revert if no functions match
0x00 0x00 revert
do_action:
NON_REENTRANT()
DO_ACTION()
UNLOCK()
}
In this example, DO_ACTION is non-reentrant, so it first uses NON_REENTRANT, but it uses the return instruction internally, which means the UNLOCK macro will never be executed, resulting in a permanently locked function.
I’m not sure the best way to handle this until a transient-storage opcode is implemented. Maybe a Huff convention could be established to have these external-function macros like DO_ACTION return a size and offset on the stack, then have the return instruction at the end.
The following would be an example of external-function macros returning the stack values instead of using the return instruction, allowing for more safe use of modifiers.
#define function doAction() view returns (uint256)
#define function otherAction() view returns (uint256)
#define constant LOCK_SLOT = FREE_STORAGE_POINTER()
#define macro NON_REENTRANT() = takes (0) returns (0) {
[LOCK_SLOT] // [lock_slot]
sload // [lock]
iszero // [is_unlocked]
unlocked // [unlocked_jumpdest]
jumpi // []
0x00 // [size]
0x00 // [offset, size]
revert // []
unlocked: // []
0x01 // [lock_value]
[LOCK_SLOT] // [lock_slot, lock_value]
sstore // []
}
#define macro UNLOCK() = takes (0) returns (0) {
0x00 // [lock_value]
[LOCK_SLOT] // [lock_slot, lock_value]
sstore // []
}
#define macro DO_ACTION() = takes (0) returns (2) {
0x45 // [value]
0x00 // [offset, value]
mstore // []
0x20 // [size]
0x00 // [offset, size]
}
#define macro OTHER_ACTION() = takes (0) returns (2) {
0x00 // [size]
0x00 // [offset, size]
}
#define macro MAIN() = takes (0) returns (0) {
// Grab the function selector from the calldata
0x00 calldataload 0xE0 shr // [selector]
dup1 __FUNC_SIG(doAction) eq do_action jumpi // [selector]
dup1 __FUNC_SIG(otherAction) eq other_action jumpi // [selector]
// Revert if no functions match
0x00 0x00 revert
do_action:
NON_REENTRANT()
DO_ACTION()
finish jump
other_action:
OTHER_ACTION()
finish jump
finish:
// stack: [offset, size]
UNLOCK()
return
}
Resources
Resources
Huff-Language
These are resources built by the Huff Language core team and its contributors.
- huff-neo: A Blazing Fast Huff Language Compiler Built In Pure Rust.
- huff-neo-project-template: Forkable Foundry project template to get you started with Huff.
- foundry-huff-neo: A Foundry Library for working with Huff contracts.
- huffmate-neo: A collection of vigorously tested, exemplary Huff contracts for demonstration purposes.
- intellij-huff-plugin: An IntelliJ Plugin for the Huff Language.
- vscode-huff: A VSCode Extension that enables developers to use the Huff Language.
Third Party Huff Contracts
These are third party huff contracts. We do not endorse and are not responsible for any liabilities or damages otherwise incurred by any material use of these contracts. Use at your own risk.
- huff-clones: A Huff rewrite of Clones-With-Immutable-Args originally written in solidity by @wighawag.
- huffmate: A library of modern, hyper-optimized, and secure Huff contracts
Other Resources
- EVM Codes: An interactive reference to Ethereum Virtual Machine Opcodes.
- A Playdate with the EVM: A concise and consumable introduction to working with the EVM.
- Ethereum EVM Illustrated: A near comprehensive visual overview of the EVM.
- Part 1, 2, 3, 4, & 5 of Noxx’s EVM Deepdive articles.
- OpenZeppelin Contracts: OpenZeppelin Contracts is a library for secure smart contract development.
Developer Guide
This section provides technical documentation for developers working on the Huff Neo compiler itself.
Topics
- Understanding Spans - How source location tracking works in the compiler
Understanding Spans
Spans are a fundamental concept in the Huff Neo compiler that track the source location of tokens, AST nodes, and bytecode. They enable accurate error reporting and source mapping for debugging.
What is a Span?
A Span represents a range of characters in the source code:
pub struct Span {
pub start: usize, // Byte offset where the span starts
pub end: usize, // Byte offset where the span ends (exclusive)
pub file: Option<Arc<FileSource>>, // Reference to the source file
}Exclusive End Convention
Huff Neo uses exclusive end positions, following Rust’s Range convention:
startpoints to the first character of the spanendpoints to the position after the last character- This matches Rust’s range syntax:
source[start..end]
Example
Given the source code:
#define macro MAIN() = takes(0) returns (0) {
0x42
add
}
The span for the token 0x42 would be:
- Text:
"0x42" - Start: 50 (position of ‘0’)
- End: 54 (position after ‘2’)
- Length: 4 characters
- Extract with:
source[50..54]→"0x42"
Working with Spans
Creating Spans
The lexer creates spans as it tokenizes:
// In the lexer, when we recognize a token:
let start = self.position; // Current position
let token_text = self.eat_while(|c| c.is_alphanumeric());
let end = self.position + token_text.len(); // Exclusive end
Token {
kind: TokenKind::Ident(token_text),
span: Span::new(start..end, file)
}Using Spans for Error Reporting
Spans enable precise error messages:
// When reporting an error:
return Err(CodegenError {
kind: CodegenErrorKind::UnmatchedJumpLabel,
span: label.span, // Points exactly to the problematic label
token: Some(label.clone()),
});This produces output like:
Error: Unmatched jump label
--> example.huff:5:8
|
5 | unknown_label jumpi
| ^^^^^^^^^^^^^
Span Preservation During Compilation
Spans flow through the compilation pipeline:
- Lexer → Creates initial spans for tokens
- Parser → Combines token spans into AST node spans
- Codegen → Preserves spans when generating bytecode
- Source Maps → Maps bytecode positions back to source spans
Special Cases
Macro Expansion
When expanding macros, we preserve the span of the actual operation, not the invocation:
#define macro ADD() = takes(2) returns (1) {
add // Span points here
}
#define macro MAIN() = takes(0) returns (0) {
0x01
0x02
ADD() // NOT here - we want the span of 'add', not 'ADD()'
}
The source map for the add opcode points to line 2, not line 8.
Constants and Arguments
For constants and macro arguments, the span includes the brackets:
#define constant VALUE = 0x42
#define macro MAIN() = takes(0) returns (0) {
[VALUE] // Span covers all of "[VALUE]" including brackets
}
Jump Labels
Jump labels have two different spans:
- Label definition:
label:- Span covers “label:” - Label reference:
label jumpi- Span covers just “label”
Common Pitfalls
Off-by-One Errors
Remember that end is exclusive:
// WRONG - treats end as inclusive
let text = &source[span.start..=span.end];
// CORRECT - end is exclusive
let text = &source[span.start..span.end];Multi-byte Characters
Spans use byte offsets, not character counts. Be careful with UTF-8:
// The lexer handles this correctly by using byte positions
let end_position = self.position + char.len_utf8();Empty Spans
Empty spans (where start == end) are valid and used for:
- EOF tokens
- Inserted/synthetic tokens
- Zero-width positions
Contributing
Overview
Contributions are welcome for all huff-neo ecosystem repositories, with huff-neo being the primary repository for Huff Language Syntax and Compilation.
Welcome, and thanks for having an interest in contributing to the Huff Language and related repositories!
All contributions are welcome! We want to make contributing to this project as easy as possible, whether it’s a bug, a feature, or a fix. We are always looking for contributors to help us improve the project.
Contributing to Huff Language is not just limited to writing code. It can mean a wide array of things, such as participating in discussions in our Telegram or reporting issues.
Issues
We use GitHub issues to track public bugs. Report a bug by opening a new issue; it’s that easy!
To run examples, make sure you update git submodules to pull down the huffmate-neo submodule by running git submodule update.
Pull Requests
We are always looking for contributors to help us improve the project.
Before submitting a PR, please make sure to run the following commands:
make pre-release